当前端到端智能驾驶技术发展迅速,SparseDrive 作为代表性模型受行业关注。工程化落地时,其模型导出与性能评测环节存在普遍技术挑战,涉及架构与环境兼容性、算子适配等多维度。为推动端到端智驾技术社区化发展,本文梳理 SparseDrive 从 ONNX 导出到硬件部署的技术链路,剖析算子替换、编译报错修复、量化策略优化等案例,构建含环境配置、数据集处理、权重管理、配置工程化的全流程技术指南,为社区提供可复用的端到端模型工程化方案,加速智驾模型从研究到车规级部署转化。
代码库:https://github.com/swc-17/SparseDrive
2. 环境部署解压公版代码包,然后创建 python 虚拟环境:
conda create -n sparsedrive python=3.8 -yconda activate sparsedrivepip3 install --upgrade pip#whl包获取:curl -O -u 'openexplorer:c5R,2!pG' ftp://vrftp.horizon.ai/misc_j5/torch/torch-1.13.0+cu116-cp38-cp38-linux_x86_64.whlcurl -O -u 'openexplorer:c5R,2!pG' ftp://vrftp.horizon.ai/misc_j5/torch/torchvision-0.14.0+cu116-cp38-cp38-linux_x86_64.whlpip3 install torch-1.13.0+cu116-cp38-cp38-linux_x86_64.whlpip3 install torchvision-0.14.0+cu116-cp38-cp38-linux_x86_64.whl pip3 install torchaudio==0.13.0cd ~/SparseDrive-main
直接 pip3 install -r requirement.txt 会报错,这里打算逐个安装 whl 包。
2.1 升级 gcc(for 安装 mmcv-full)步骤 1:安装新版 GCC/G++使用 conda 安装,不会破坏系统自带的 GCC 4.8.5:
安装 GCC 10
conda install -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge gcc_linux-64=10 gxx_linux-64=10
安装完成后,你会在 Conda 环境里有新 GCC,例如:
$ which gcc
/home/users/yue01.chen/anaconda3/envs/sparsedrive/bin/x86_64-conda-linux-gnu-gcc
步骤 2:指定编译器环境变量为了确保 pip 编译 mmcv-full 时使用 Conda 的新版 GCC,而不是系统 4.8.5,需要设置环境变量:
export CC=$(which x86_64-conda-linux-gnu-gcc) export CXX=$(which x86_64-conda-linux-gnu-g++)
步骤 3:卸载旧的 mmcv/mmcv-full可以把这两行添加到 。bashrc 或 。zshrc 中,保证每次激活环境自动生效。
pip uninstall mmcv mmcv-full -y
步骤 4:从源码编译 mmcv-full使用 --no-binary 强制从源码编译:
pip install mmcv-full==1.7.1 --force-reinstall --no-cache-dir --no-binary mmcv-full
步骤 5:验证安装说明:
--no-binary mmcv-full 表示不使用预编译 wheel,直接编译 C++/CUDA 扩展。
--force-reinstall + --no-cache-dir 可以避免 pip 缓存的旧版本干扰。
Python 中验证 mmcv-full GPU 扩展是否可用:
import mmcv from mmcv.ops import nms_match print("mmcv-full GPU extensions are ready!")
如果报错 ModuleNotFoundError: No module named 'mmcv。_ext',说明编译仍有问题,需要检查:
GCC 版本 ≥ 7
CUDA 环境变量 CUDA_HOME 是否指向 /home/users/yue01.chen/cuda-11.8
nvcc 可用 (nvcc --version)
后续在运行中缺乏什么库就直接 pip3 install 即可。
3. 创建数据集与权重下载3.1 生成 pkl从官网下载 nuscenes 数据集,解压后把 expansion 文件夹放到 maps 下,
然后运行:
sh scripts/create_data.sh
代码运行完成会在 data/info 目录下生成:
├── data│ ├── infos │ │ ├── mini │ │ ├── nuscenes_infos_train.pkl │ │ └── nuscenes_infos_val.pkl
报错的时候把这个注释了:
报错的时候把这个注释了:
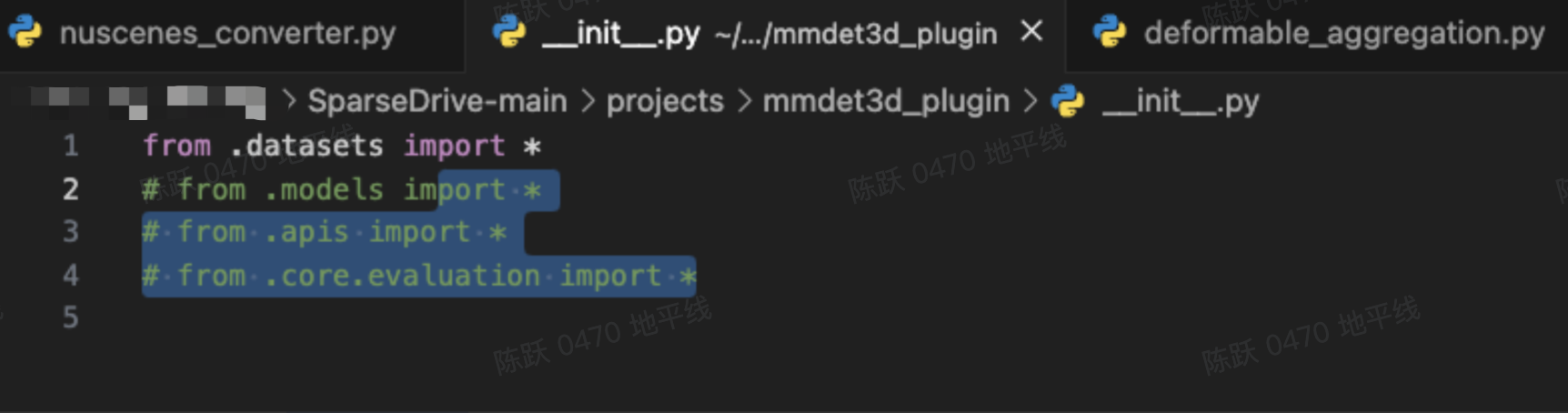
sh scripts/kmeans.sh3.3 权重下载
https://github.com/swc-17/SparseDrive/releases/download/v1.0/sparsedrive_stage1.pth https://github.com/swc-17/SparseDrive/releases/download/v1.0/sparsedrive_stage2.pth
https://download.pytorch.org/models/resnet50-19c8e357.pth
下载完成后放在 ckpt 文件夹。
4. config 文件修改#单卡单batchtotal_batch_size = 1num_gpus = 1#使用pytorch实现的dfause_deformable_func = False # mmdet3d_plugin/ops/setup.py needs to be executed#导出的onnx不要with_motion_plan,因为跑验证集的时候发现这部分跑不通task_config = dict( with_det=True, with_map=True, with_motion_plan=False,
另外,还有非常重要的一点,config 文件中的 MultiheadFlashAttention 都替换为普通的 MultiheadAttention。
5. 导出脚本和适配修改导出思路:为了不大幅侵入源码,在导出脚本里重写了 forward,并增加环境变量进行控制
5.1 去除后处理使用环境变量 my_var=="export_to_onnx"进行控制:
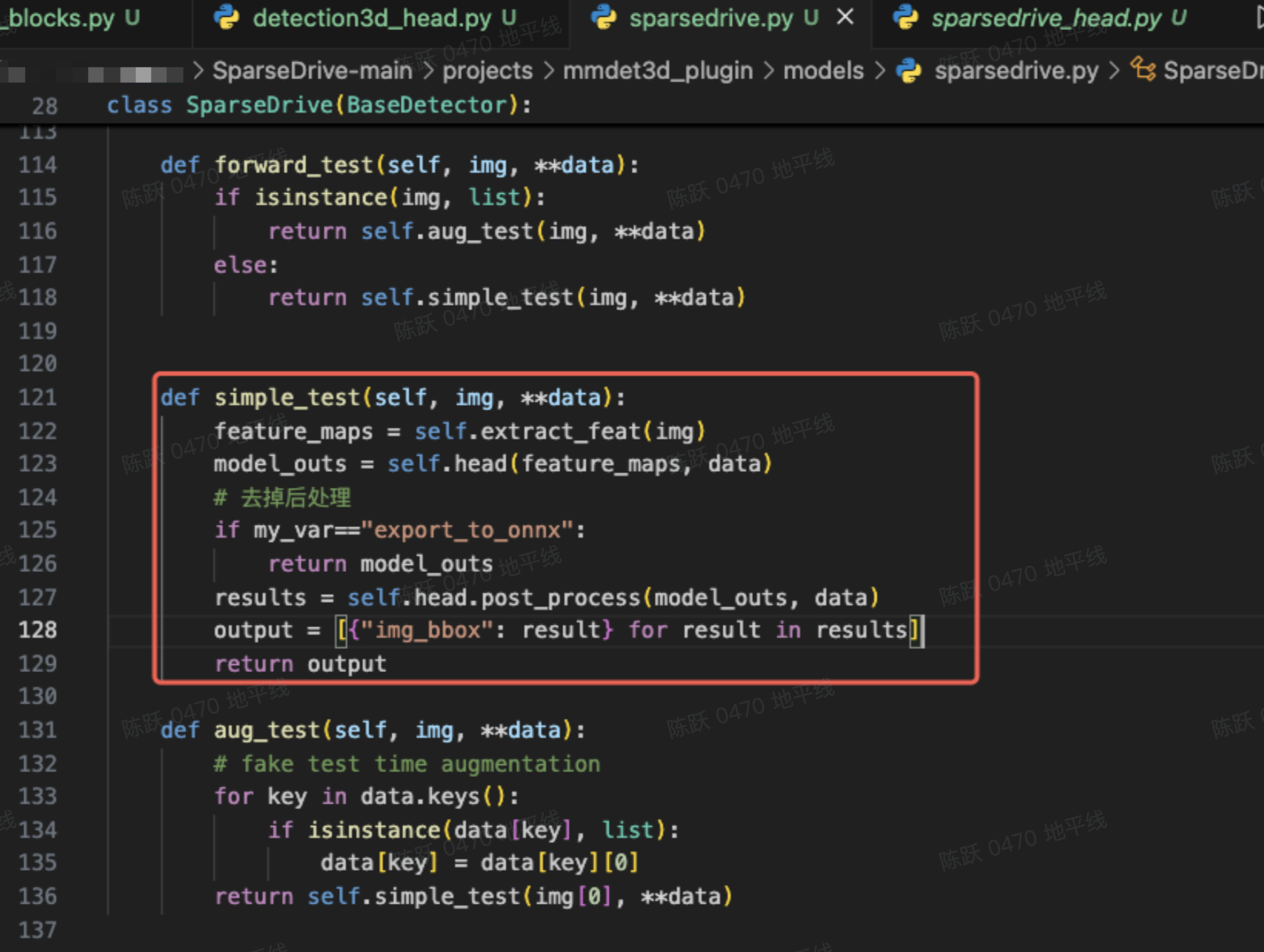
在 tools 文件夹下构建 forward_export.py,重写 sparsedrive、det_head 和 map_head 的 orward 函数,如下所示:
from typing import List, Optional, Tuple, Unionimport warningsimport numpy as npimport torchimport torch.nn as nn#为了适配输入的形式和时序输入,重写了"SparseDrive" 类的forwarddef simple_test_onnx_wrapper(self, img, T_global, T_global_inv, timestamp, projection_mat, image_wh, ego_status,cached_anchor,cached_feature,mask,cached_confidence,cached_map_anchor,cached_map_feature,cached_map_confidence):
data = { "img_metas": [{5.3 self.instance_bank.get_for_export_det_onnx()函数路径:SR/12yuanrong/SparseDrive-main/projects/mmdet3d_plugin/models/instance_bank.py
def get_for_export_det_onnx(self, batch_size, metas=None, dn_metas=None): instance_feature = self.instance_feature.unsqueeze(0).repeat(batch_size, 1, 1) anchor = self.anchor.unsqueeze(0).repeat(batch_size, 1, 1) #从上一帧的时序输出中获取输入 cached_anchor = metas["cached_anchor"] cached_feature = metas["cached_feature"] self.mask = metas["mask"] self.confidence = metas["cached_confidence"] time_interval=metas["img_metas"][0]["timestamp"]5.4 self.instance_bank.get_for_export_map_onnx()函数
路径:SparseDrive-main/projects/mmdet3d_plugin/models/instance_bank.py
def get_for_export_map_onnx(self, batch_size, metas=None, dn_metas=None): instance_feature = self.instance_feature.unsqueeze(0).repeat(batch_size, 1, 1) anchor = self.anchor.unsqueeze(0).repeat(batch_size, 1, 1) cached_anchor = metas["cached_map_anchor"] cached_feature = metas["cached_map_feature"] self.mask = metas["mask"] self.confidence = metas["cached_map_confidence"] time_interval=metas["img_metas"][0]["timestamp"] return (5.5 修改导出会报错的代码报错 1
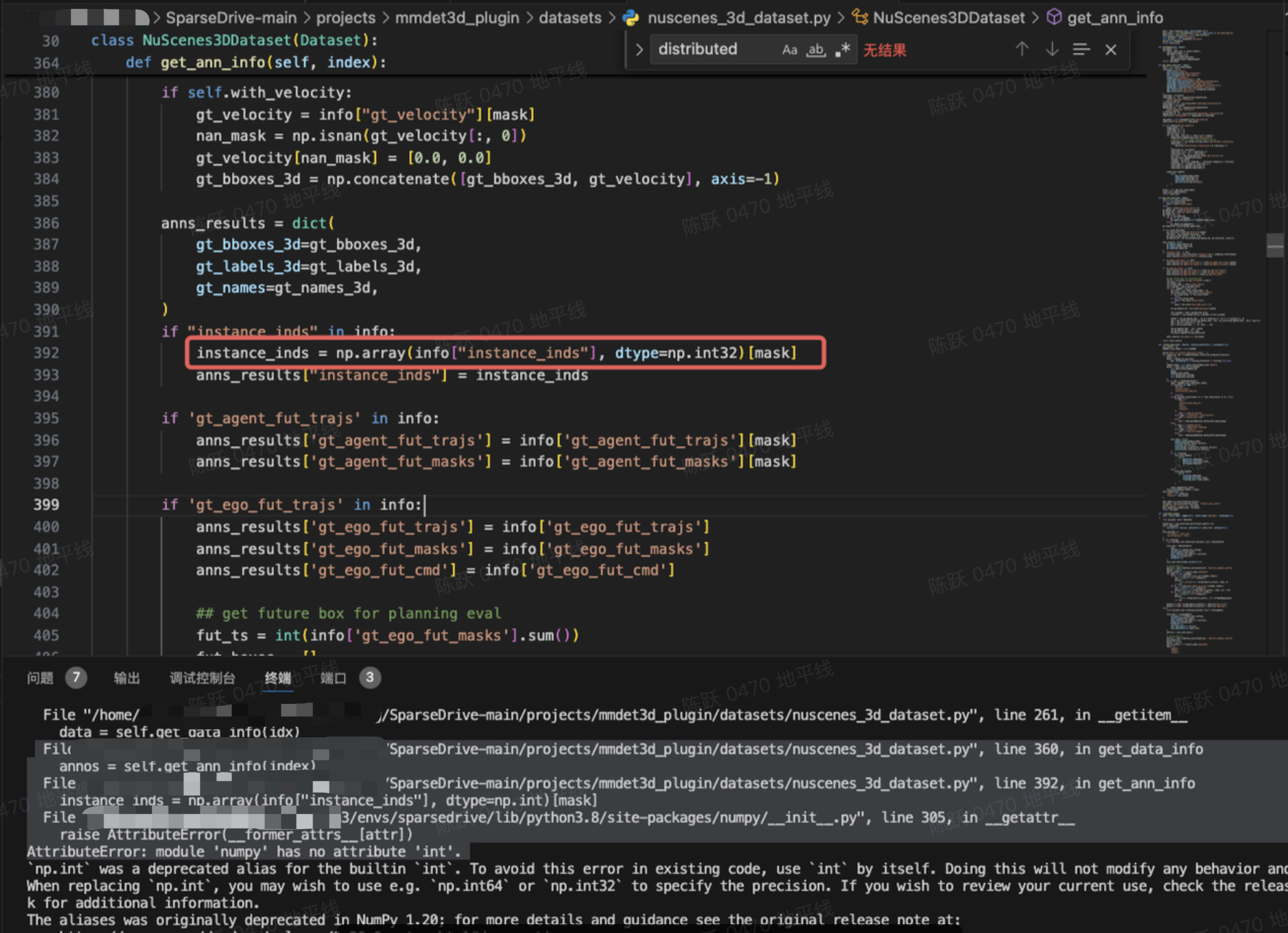 将 instance_inds 修改为 np.int32 类型。
将 instance_inds 修改为 np.int32 类型。
报错:
traceback : Traceback (most recent call last): File "/home/users/yue01.chen/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/distributed/elastic/multiprocessing/errors/__init__.py", line 346, in wrapper return f(*args, **kwargs) File "./tools/export_onnx.py", line 314, in main torch.onnx.export( File "/home/users/yue01.chen/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/utils.py", line 504, in export _export( File "/home/users/yue01.chen/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/utils.py", line 1529, in _export graph, params_dict, torch_out = _model_to_graph( File "/home/users/yue01.chen/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/utils.py", line 1115, in _model_to_graph
报错原因:
PyTorch 的 aten::tile 运算符在 ONNX opset 17 中没有对应的实现,所以导出失败。
解决办法
把 torch.tile 替换成等价的 repeat
在 PyTorch 里,torch.tile 其实就是 repeat 的一个封装,功能等价。 而 repeat 在 ONNX 里是受支持的(映射到 Repeat 节点)。
解决办法:
把 self.instance_bank.get_for_export_det_onnx()和 self.instance_bank.get_for_export_map_onnx()函数中的
instance_feature = torch.tile( self.instance_feature[None], (batch_size, 1, 1) )anchor = torch.tile(self.anchor[None], (batch_size, 1, 1))
修改成 repeat 实现,如下:
instance_feature = self.instance_feature.unsqueeze(0).repeat(batch_size, 1, 1)anchor = self.anchor.unsqueeze(0).repeat(batch_size, 1, 1)报错 3(重要)
报错截图:
File "/home/users/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/utils.py", line 504, in export _export( File "/home/users/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/utils.py", line 1529, in _export graph, params_dict, torch_out = _model_to_graph( File "/home/users/naconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/utils.py", line 1115, in _model_to_graph graph = _optimize_graph( File "/home/users/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/utils.py", line 663, in _optimize_graph graph = _C._jit_pass_onnx(graph, operator_export_type) File "/home/users/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/utils.py", line 1867, in _run_symbolic_function return symbolic_fn(graph_context, *inputs, **attrs) File "/home/users/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/symbolic_opset9.py", line 6664, in onnx_placeholder return torch._C._jit_onnx_convert_pattern_from_subblock(block, node, env) File "/home/users/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/utils.py", line 1867, in _run_symbolic_function return symbolic_fn(graph_context, *inputs, **attrs) File "/home/users/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/symbolic_opset11.py", line 230, in index_put if symbolic_helper._is_bool(indices_list[idx_]): File "/home/users/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/symbolic_helper.py", line 736, in _is_bool return _is_in_type_group(value, {_type_utils.JitScalarType.BOOL}) File "/home/users/anaconda3/envs/sparsedrive/lib/python3.8/site-packages/torch/onnx/symbolic_helper.py", line 708, in _is_in_type_group scalar_type = value.type().scalarType() RuntimeError: r INTERNAL ASSERT FAILED at "../aten/src/ATen/core/jit_type_base.h":547, please report a bug to PyTorch.报错原因:
ONNX 导出失败的根因是图里某处会把一个标量常量以没有 dtype(即 None) 的形式传给了 ONNX 导出器,导致 torch.onnx。_type_utils.JitScalarType.from_name 收到 None 并抛出 ValueError: Scalar type name cannot be None。这类情况常在用高级索引/原地赋值(tensor[index] = other、index_put、masked_scatter 等)时出现,导出器有时会把标量常量漏掉 dtype。
优先级修复建议(按顺序尝试)
定位问题代码:查找模型中类似 x[:, idx] = y、x[index] = y、index_put、masked_scatter、masked_fill 的用法。也可在 torch.onnx.export(..., verbose=True) 打印的导出图里查找 aten::index_put、index_put、prim::ListConstruct 等节点位置。
把原地/索引赋值改写为 ONNX 友好的算子:常用替代方法:
用 scatter:
x = x.clone() x = x.scatter(dim, indices.unsqueeze(-1).expand(...), y)
用布尔 mask + torch.where:
mask = torch.zeros_like(x, dtype=torch.bool) mask[:, indices] = True x = torch.where(mask, y_broadcasted, x)
这两种通常能被 ONNX 导出器更好地支持。
确保传入 torch.onnx.export 的示例输入都有明确 dtype(不要传 None 或 Python 原始标量),例如 tensor.float(). cuda()、indices.long().cuda()。
尝试不同的 opset 或更新 PyTorch:有些导出器 bug 在较新 opset 或 PyTorch 版本里被修复。可试 opset_version=12、14 等;若可行,升级 PyTorch 往往能解决这类问题。
临时回退方案:如果短时间无法改模型,可使用 ATen fallback(operator_export_type=OperatorExportTypes.ONNX_ATEN_FALLBACK)导出,得到包含 ATen 节点的 ONNX(不适合生产但便于调试)。
不要修改 site-packages(除非非常了解风险):虽然可以在 _type_utils.from_name 做防守性修改防止报错,但这不是长期或推荐的做法。
通过二分法定位到是 refine 模块的报错(即在 refine 模块前 return 导出 onnx 不报错,经过 refine 层以后 return 会报错),然后逐渐定位到其中的这个部分触发了上述 1 中的错误,如下:
output[..., self.refine_state] = (# output[..., self.refine_state] + anchor[..., self.refine_state]# )# if self.normalize_yaw:# output[..., [SIN_YAW, COS_YAW]] = torch.nn.functional.normalize(# output[..., [SIN_YAW, COS_YAW]], dim=-1# )# if self.output_dim > 8:# if not isinstance(time_interval, torch.Tensor):# time_interval = instance_feature.new_tensor(time_interval)
修改后的代码:
@PLUGIN_LAYERS.register_module()class SparseBox3DRefinementModule(BaseModule): def __init__( self, embed_dims=256, output_dim=11, num_cls=10, normalize_yaw=False, refine_yaw=False, with_cls_branch=True,5.6 scatternd 消除
由于征程 6 工具链目前只支持 CPU 实现的 scatternd,所以在导出 onnx 的时候把这部分替换成 slice+concat 的实现。
路径:SparseDrive-main/projects/mmdet3d_plugin/models/detection3d/detection3d_blocks.py
def forward( self, anchor, instance_feature=None, T_cur2temp_list=None, cur_timestamp=None, temp_timestamps=None, ): bs, num_anchor = anchor.shape[:2] size = anchor[..., None, [W, L, H]].exp()5.7 导出代码
导出脚本 export_onnx.py 基于 SparseDrive-main/tools/test.py 进行编写,其具体实现如下:
# Copyright (c) OpenMMLab. All rights reserved.import argparseimport mmcvimport osfrom os import path as ospimport torchimport warningsfrom mmcv import Config, DictActionfrom mmcv.cnn import fuse_conv_bn
另外,需要对 tools/dist_test.sh 进行修改如下;
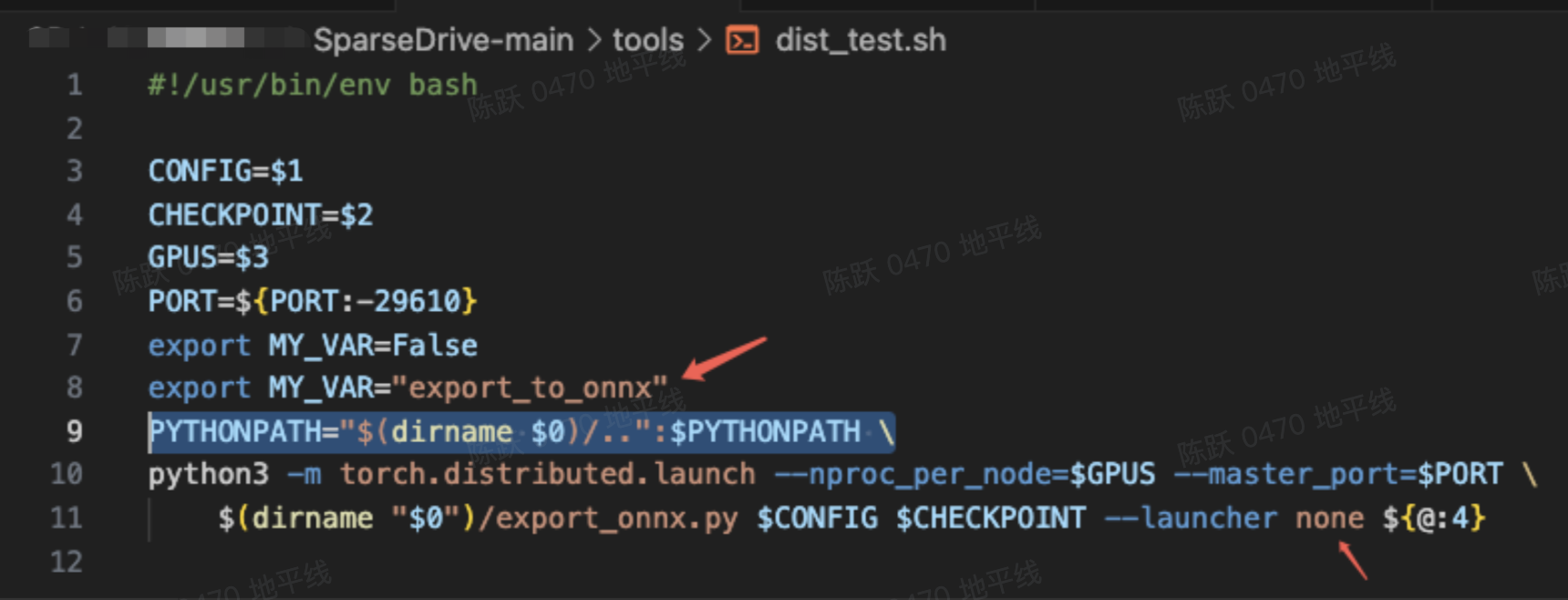 导出脚本运行:
导出脚本运行:
bash scripts/test.sh5.9 cache 过程的 scatternd 和 Cast 算子消除(如果模型中存在 cache 过程的话)
如果想要在模型中增加输出 cache 的功能,即在 forward_export.py 的函数中增加以下代码:
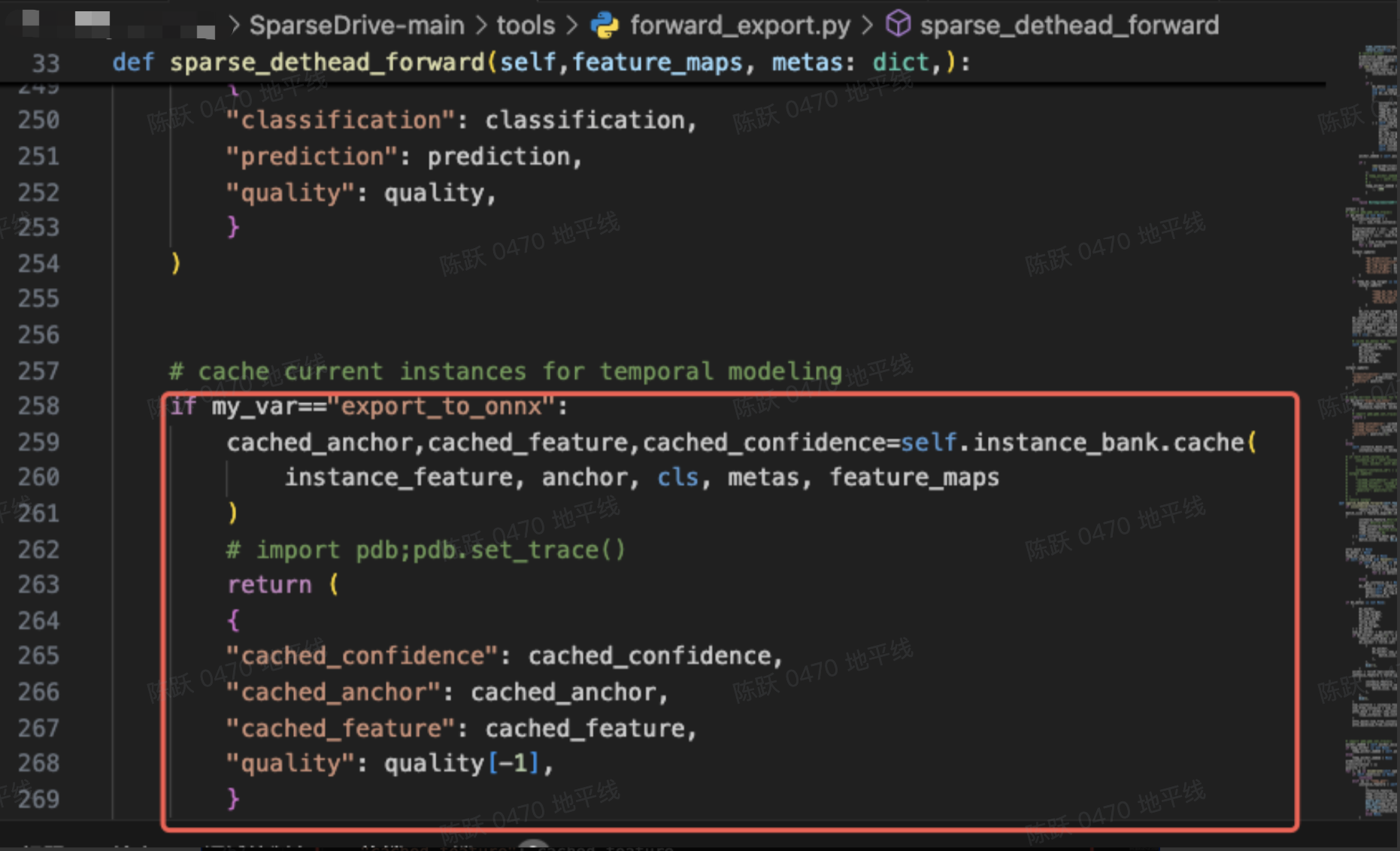 但是公版的 self.instance_bank.cache()函数的写法会引入工具链只能在 CPU 上支持的 ScatterND 算子和 Cast 算子,所以这里需要对代码做两处适配。
但是公版的 self.instance_bank.cache()函数的写法会引入工具链只能在 CPU 上支持的 ScatterND 算子和 Cast 算子,所以这里需要对代码做两处适配。
路径:SparseDrive-main/projects/mmdet3d_plugin/models/instance_bank.py 中的 cache 函数:
if self.confidence is not None: # confidence[:, : self.num_temp_instances] = torch.maximum( # self.confidence[0] * self.confidence_decay, # confidence[:, : self.num_temp_instances], # ) left = torch.maximum( self.confidence[0] * self.confidence_decay, confidence[:, :self.num_temp_instances],) right = confidence[:, self.num_temp_instances:] confidence = torch.cat([left, right], dim=1)5.9.2 消除 cast 算子:
路径:SparseDrive-main/projects/mmdet3d_plugin/models/instance_bank.py 中的 topk 函数:
def topk(confidence, k, *inputs): # bs, N = confidence.shape[:2] # confidence, indices = torch.topk(confidence, k, dim=1) # indices = ( # indices + torch.arange(bs, device=indices.device)[:, None] * N # ).reshape(-1) # outputs = [] # for input in inputs: # outputs.append(input.flatten(end_dim=1)[indices].reshape(bs, k, -1)) bs, N = confidence.shape[:2]6. 性能评测6.1 算子支持情况
nash-p 下可以编译成功
修改模型后,所有算子支持 BPU 实现
b30.binary_eltwise : 2071 b30.conv2d : 503 b30.gather2d : 10 b30.lut : 314 b30.pool2d : 1 b30.reduce : 528 b30.resize2d : 3 b30.warp : 48 b30vpu.dequantize : 9 b30vpu.quantize : 86.2 静态 per 性能分析6.2.1 确定性能瓶颈
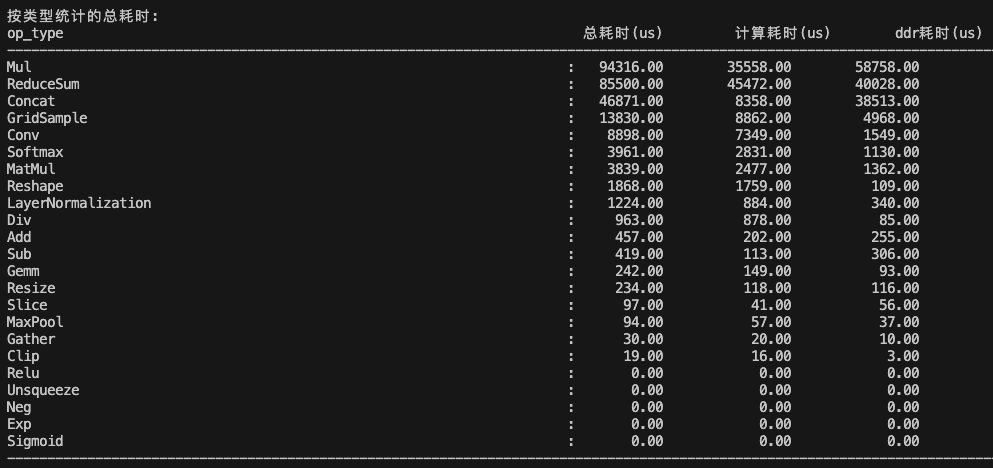
获取到 perf.html 和 perf.json 后,使用【新版 perf 文件解读与性能分析】附录中的脚本对性能进行分析,输入为 perf.json,输出如下所示:
按照算子类型统计的耗时:
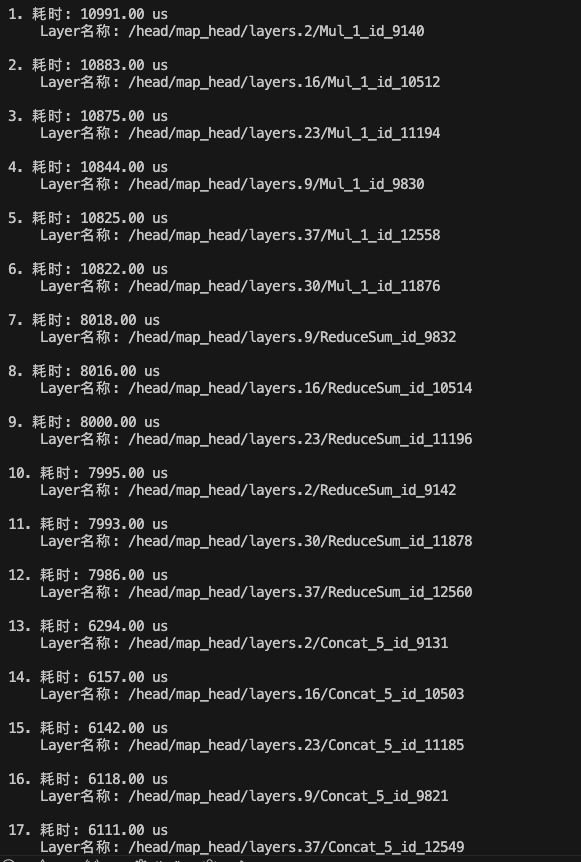
 耗时排名 TOP20 的算子:
耗时排名 TOP20 的算子:
 根据以上信息,可以得出优化目标:
根据以上信息,可以得出优化目标:
Mul 和 ReduceSum 算子的耗时最久,而且 mul 算子 ddr 耗时超过计算耗时的 65%,引发了带宽问题;
ToP12 耗时的算子就是 Mul 和 ReduceSum,所以重点是优化 Mul 和 ReduceSum 算子。
查看模型结构发现,模型中耗时的 Mul 和 ReduceSum 都处于这样的子结构中,所以我们主要是对这个结构进行性能优化。
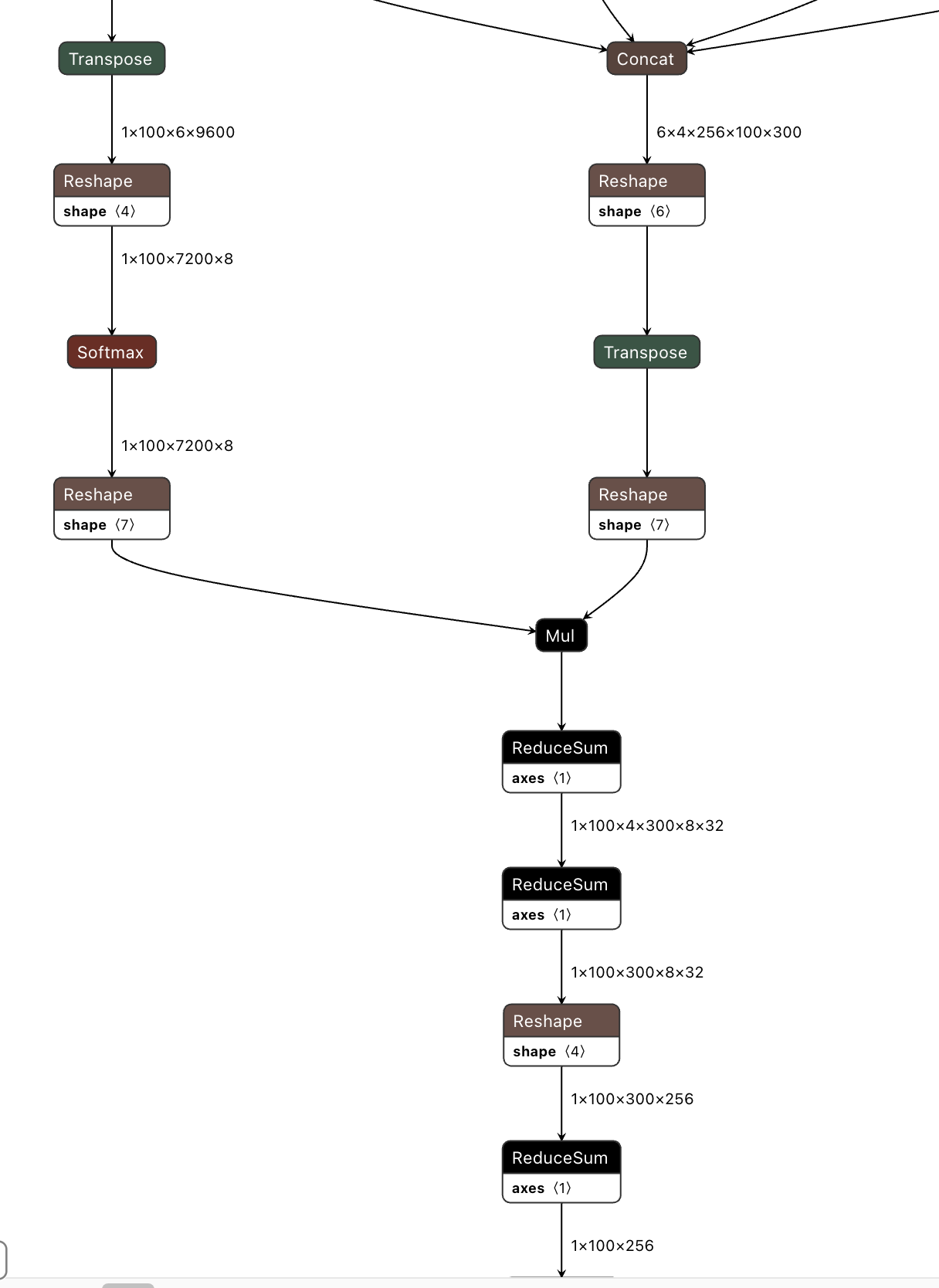 此结构主要由 Mul、ReduceSum 和数据搬运算子组成,一方面 MulReduceSum 是运行在专门做向量计算的 VAE,加速效果不如张量,另一方面输入的 shape 非常大,也就解释了为何会引发带宽问题。、
此结构主要由 Mul、ReduceSum 和数据搬运算子组成,一方面 MulReduceSum 是运行在专门做向量计算的 VAE,加速效果不如张量,另一方面输入的 shape 非常大,也就解释了为何会引发带宽问题。、
所以这里考虑将 Mul+ReduceSum 计算替换为等价的 Mamtmul,从而使得这部分计算在 VAE 上加速。
性能优化效果验证这里主要有以下步骤:
**替换为 Matmul 计算:**根据上述子图结构将其替换为 Matmul 计算,并导出 optimized.onnx;
**替换等价性验证:**在原始 onnx 中提取上述子图,和 optimized.onnx 进行输出一致性验证;
**性能评测:**同时对原始 onnx 子图和 optimized.onnx 进行 fast-perf,验证性能收益。
上述步骤可以参考:https://developer.horizon.auto/blog/13065
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。


