该示例为参考算法,仅作为在征程 6 上模型部署的设计参考,非量产算法
一、简介
高清地图是自动驾驶系统的重要组件,提供精确的驾驶环境信息和道路语义信息。传统离线地图构建方法成本高,维护复杂,使得依赖车载传感器的实时感知建图成为新趋势。早期实时建图方法存在局限性,如处理复杂地图元素的能力不足、缺乏实例级信息等,在实时性和后处理
复杂度上存在挑战。
为了解决这些问题,基于 Transformer 的 MapTR 模型被提出,它采用端到端结构,仅使用图像数据就能实现高精度建图,同时保证实时性和鲁棒性。MapTRv2 在此基础上增加了新特性,进一步提升了建图精度和性能。
地平线面向智驾场景推出的征程 6 系列(征程 6)芯片,在提供强大算力的同时带来了极致的性价比,征程 6 芯片对于 Transformer 模型的高效支持助力了 MapTR 系列模型的端侧部署。本文将详细介绍地平线算法工具链在征程 6 芯片部署 MapTR 系列模型所做的优化以及模型端侧的表现。
二、性能精度指标
模型配置:

性能精度表现:

三、公版模型介绍
3.1 MapTR
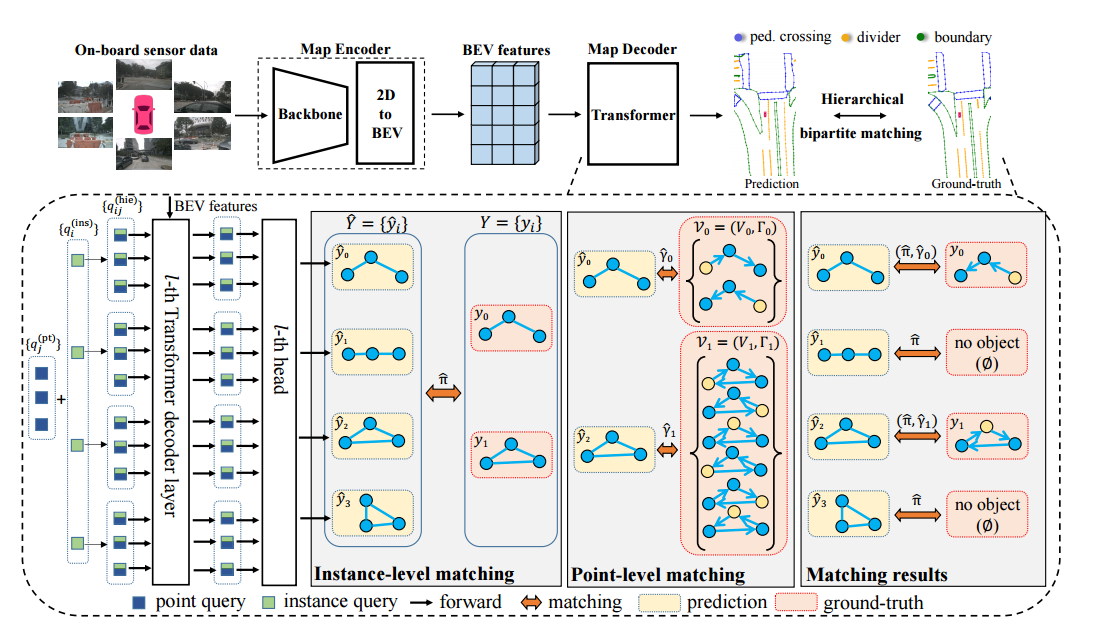
MapTR 模型的默认输入是车载摄像头采集到的 6 张相同分辨率的环视图像,使用 nuScenes 数据集,同时也支持拓展为多模态输入例如雷达点云。模型输出是矢量化的地图元素信息,其中地图元素为人行横道、车道分隔线和道路边界 3 种。模型主体采用 encoder-decoder 的端到端结构:
3.2 MapTRv2
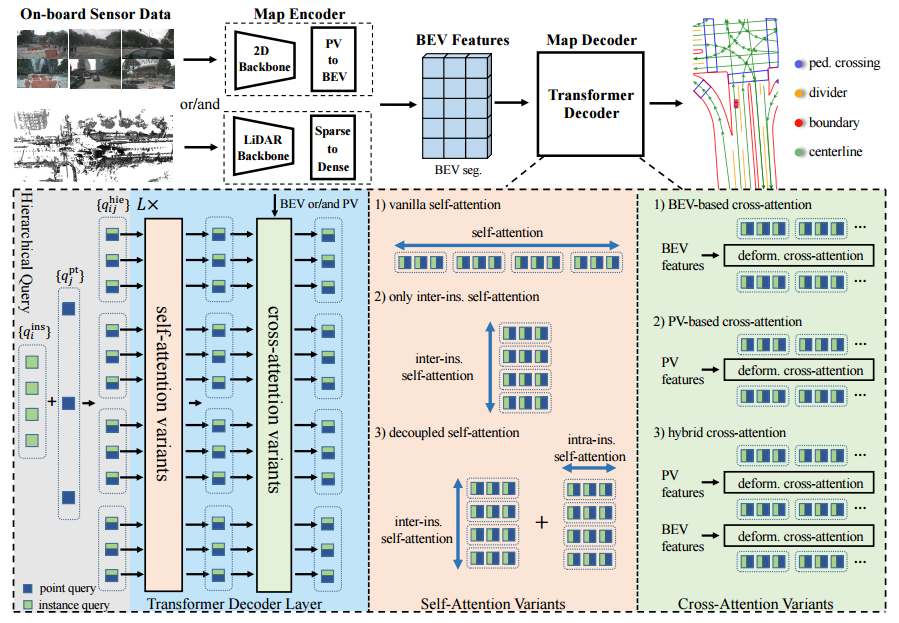
MapTRv2 在 MapTR 的基础上增加了新的特性:
四、地平线部署说明
地平线参考算法使用流程请参考征程 6 参考算法使用指南;对应高效模型设计建议请参考《征程 6 平台算法设计建议》
MapTROE 模型引入了 SD map 的前融合结构,与图像视角转换后的 bev feature 进行融合,再通过优化后的 MapTR head 生成矢量化的地图元素。整体结构如下:
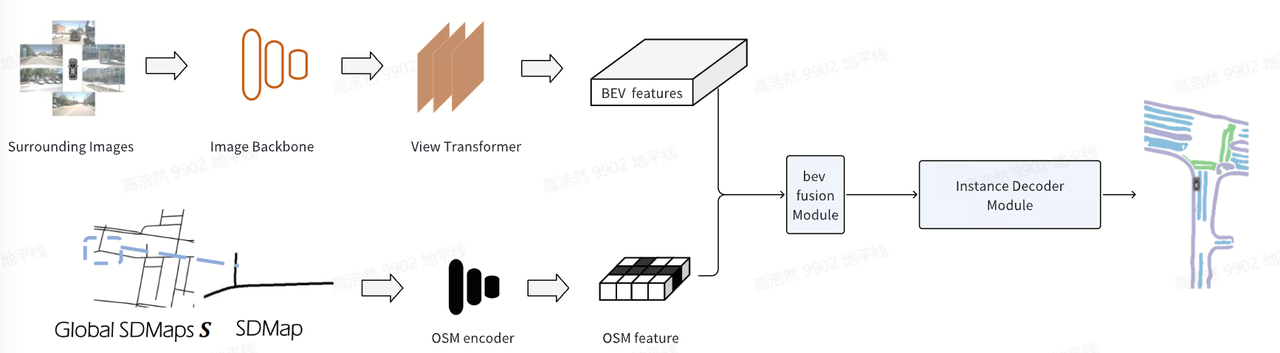
因此 maptroe_henet_tinym_bevformer_nuscenes 模型相比之前版本新增了如下优化点:
maptroe_henet_tinym_bevformer_nuscenes 模型对应的代码路径:

4.1 性能优化
4.1.1 Backbone
MapTROE 采用基于征程 6 芯片的高效轻量化 Backbone HENet_TinyM(Hybrid Efficient Network, Tiny for J6M),HENet 能更好地利用征程 6 系列芯片的算力,在模型精度和性能上更具优势。HENet_TinyM 采用了纯 CNN 架构,总体分为四个 stage,每个 stage 会进行一次 2 倍下采样,具体结构配置如下:
# henet-tinym depth = [4, 3, 8, 6] block_cls = ["GroupDWCB", "GroupDWCB", "AltDWCB", "DWCB"] width = [64, 128, 192, 384] attention_block_num = [0, 0, 0, 0] mlp_ratios, mlp_ratio_attn = [2, 2, 2, 3], 2 act_layer = ["nn.GELU", "nn.GELU", "nn.GELU", "nn.GELU"] use_layer_scale = [True, True, True, True] extra_act = [False, False, False, False] final_expand_channel, feature_mix_channel = 0, 1024 down_cls = ["S2DDown", "S2DDown", "S2DDown", "None"] patch_embed = "origin"
4.1.2 Neck
Neck 部分采用了地平线内部实现的 FPN,相比公版 FPN 实现,在征程 6 平台上性能更加友好。
4.1.3 View Transformer
地平线参考算法版本将基于 LSS 的视角转换方式替换为深度优化后 Bevformer 的 View Transformer 部分。
# 公版模型
class MapTRPerceptionTransformer(BaseModule):
...
def attn_bev_encode(...):
...
if prev_bev is not None:
if prev_bev.shape[1] == bev_h * bev_w:
prev_bev = prev_bev.permute(1, 0, 2)
if self.rotate_prev_bev:
for i in range(bs):
# num_prev_bev = prev_bev.size(1)
rotation_angle = kwargs['img_metas'][i]['can_bus'][-1]
tmp_prev_bev = prev_bev[:, i].reshape(
bev_h, bev_w, -1).permute(2, 0, 1)
tmp_prev_bev = rotate(tmp_prev_bev, rotation_angle,
center=self.rotate_center)
tmp_prev_bev = tmp_prev_bev.permute(1, 2, 0).reshape(
bev_h * bev_w, 1, -1)
prev_bev[:, i] = tmp_prev_bev[:, 0]
# add can bus signals
can_bus = bev_queries.new_tensor(
[each['can_bus'] for each in kwargs['img_metas']]) # [:, :]
can_bus = self.can_bus_mlp(can_bus[:, :self.len_can_bus])[None, :, :]
bev_queries = bev_queries + can_bus * self.use_can_bus
...
# 地平线参考算法
class BevFormerViewTransformer(nn.Module):
...
def __init__(...):
...
self.prev_frame_info = {
"prev_bev": None,
"scene_token": None,
"ego2global": None,
}
...
def get_prev_bev(...):
if idx == self.queue_length - 1 and self.queue_length != 1:
prev_bev = torch.zeros(
(bs, self.bev_h * self.bev_w, self.embed_dims),
dtype=torch.float32,
device=device,
)
...
else:
prev_bev = self.prev_frame_info["prev_bev"]
if prev_bev is None:
prev_bev = torch.zeros(
(bs, self.bev_h * self.bev_w, self.embed_dims),
dtype=torch.float32,
device=device,
) # 对应改动2.a
...
def bev_encoder(...):
...
tmp_prev_bev = prev_bev.reshape(
bs, self.bev_h, self.bev_w, self.embed_dims
).permute(0, 3, 1, 2)
prev_bev = F.grid_sample(
tmp_prev_bev, norm_coords, "bilinear", "zeros", True
) # 对应改动2.b
...
class SingleBevFormerViewTransformer(BevFormerViewTransformer):
...
def get_bev_embed(...):
...
bev_query = self.bev_embedding.weight
bev_query = bev_query.unsqueeze(1).repeat(1, bs, 1) # 对应改动2.c
...d. 取消了公版的 TemporalSelfAttention,改为 HorizonMSDeformableAttention,保持精度的同时提升速度;
# 公版模型Config model = dict( ... pts_bbox_head=dict( type='MapTRHead', ... transformer=dict( type='MapTRPerceptionTransformer', ... encoder=dict( type='BEVFormerEncoder', ... transformerlayers=dict( type='BEVFormerLayer', attn_cfgs=[ dict( type='TemporalSelfAttention', embed_dims=_dim_, num_levels=1), ... ] ) ) ) ) ) # 地平线参考算法Config model = dict( ... view_transformer=dict( type="SingleBevFormerViewTransformer", ... encoder=dict( type="SingleBEVFormerEncoder", ... encoder_layer=dict( type="SingleBEVFormerEncoderLayer", ... selfattention=dict( type="HorizonMSDeformableAttention", # 对应改动2.d ... ), ) ) ) )
e. 支持公版 Bevformer 中的 bev_mask,并将涉及到的 gather/scatter 操作,用 gridsample 等价替换,提高模型速度。
# 地平线参考算法Config view_transformer=dict( type="SingleBevFormerViewTransformer", ... max_camoverlap_num=2, # 对应根据bev_mask进行稀疏映射,提高运行效率,对应改动2.e virtual_bev_h=int(0.4 * bev_h_), virtual_bev_w=bev_w_, ... )
4.1.4 Head
公版 MapTR 使用分层 query 机制,定义一组 instance queries 和由所有 instance 共享的 point queries,每个地图元素对应一组分层 query(一个 instance query 和共享的 point queries 广播相加得到),在 decoder layer 中分别使用 self-attention 和 cross-attention 来更新分层 query。
MapTROE 的改进则是为每个地图元素分配一个 instance query(无直接 point query),每个 query 用于编码语义信息和地理位置信息,decoder 阶段和公版 MapTR 一样,分别进行 multi-head self-attention 和 deformable cross-attention,最后每个 instance query 通过 MLP 网络生成类别信息和元素内的点集坐标,相比公版预测分层 query,改进后直接预测 instance query 带来的计算量更少,极大地提高了模型在端侧的运行性能。同时借鉴 StreamMapNet,使用多点注意力方法来适应高度不规则的地图元素,扩大感知范围。代码见/usr/local/lib/python3.10/dist-packages/hat/models/task_modules/maptr/instance_decoder.py: class MapInstanceDetectorHead(nn.Module)
4.1.5 多点注意力
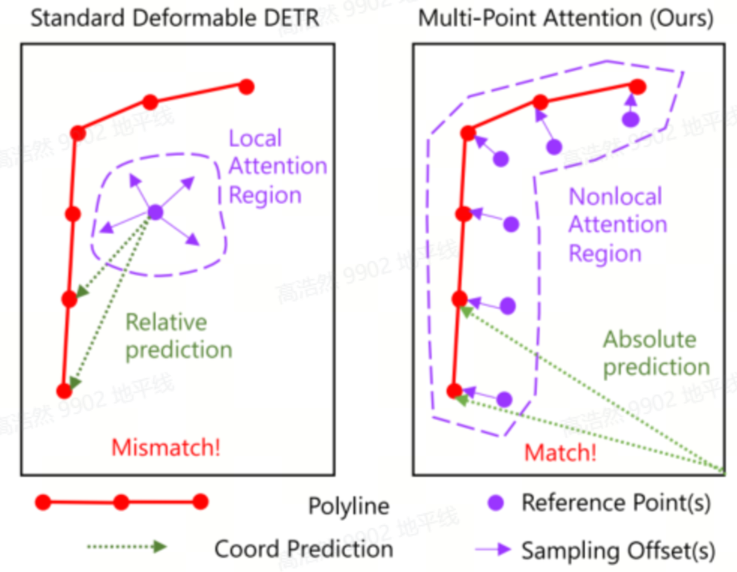 传统的可变形注意力为每个 query 分配一个参考点,多点注意力则使用前一层预测的地图元素的多个点作为当前层 query 的参考点,具体计算方式是在点维度上扩展了一层求和,将一个点变成多个点,分别计算 deformable attention。回归的时候并非预测 offsets,而是直接预测地图元素点的坐标位置。
传统的可变形注意力为每个 query 分配一个参考点,多点注意力则使用前一层预测的地图元素的多个点作为当前层 query 的参考点,具体计算方式是在点维度上扩展了一层求和,将一个点变成多个点,分别计算 deformable attention。回归的时候并非预测 offsets,而是直接预测地图元素点的坐标位置。
4.1.6Attention
模型中用到的 attention 操作均使用地平线提供的算子,相比 PyTorch 提供的公版算子,地平线 attention 算子在保持算子逻辑等价的同时在效率上进行了优化
from hat.models.task_modules.bevformer.attention import ( HorizonMSDeformableAttention, HorizonMSDeformableAttention3D, HorizonSpatialCrossAttention, ... )
4.2 精度优化
4.2.1 浮点精度
MapTROE 模型引入 SD Map 前融合,与图像转换后的 bev feature 进行融合,以提高在线地图的生成质量。模块结构如下图所示:

4.2.1.1 SD Map 特征提取
SD Map 从 OpenStreetMap(OSM)中获取,通过由 GPS 提供的车辆位姿,查询车辆当前位姿附近的 SD Map,然后将 SD Map 转换到自车坐标系下,与 NuScenes 中的数据标注坐标系保持一致。SD Map 会从车道中心骨架线 Polyline 的形式转化为栅格结构,大小和 BEV 特征相同,经过 CNN 变成特征图,对应 SD Map 的先验信息。
4.2.1.2 SD Map 特征融合
栅格化后的 SD Map 和实际场景可能会出现错位、不对齐的情况,这种错位导致直接 Concatenate BEV 特征和 SD Map 特征的效果并不好,为了解决这个问题,引入了特征融合模块,通过网络学习来决定最适合的对齐方式,可以有效地利用 SD Map 先验提升 BEV 特征的效果。关于特征融合模块,分别实验了交叉注意力与 CNN 网络,通过精度与性能的平衡,最后选择了 CNN 网络模块。
4.3 量化精度
# Config文件 cali_qconfig_setter = (default_calibration_qconfig_setter,) qat_qconfig_setter = (default_qat_fixed_act_qconfig_setter,)
2.浮点阶段采用更大的 weight decay 训练,使浮点数据分布范围更小,浮点模型参数更有利于量化
# Config文件 float_trainer = dict( ... optimizer=dict( ... weight_decay=0.1, # 相比maptrv2_resnet50_bevformer_nuscenes增大了10倍 ), ... )
3.QAT 训练采用固定较小的 learning rate 来 fine-tune,这里固定也即取消 LrUpdater Callback 的使用,配置如下:
# Config文件 qat_lr = 1e-9
4.取消了公版模型 MapTRHead 中对于量化不友好的 inverse_sigmoid 操作;此外 MapTROE 对 Head 的优化无需再引入 reg_branches 输出和 reference 相加后再 sigmoid 的操作:
# 公版模型 class MapTRHead(DETRHead): ... def forward(...): ... for lvl in range(hs.shape[0]): if lvl == 0: # import pdb;pdb.set_trace() reference = init_reference else: reference = inter_references[lvl - 1] reference = inverse_sigmoid(reference) ... tmp = self.reg_branches[lvl](...) tmp[..., 0:2] += reference[..., 0:2] tmp = tmp.sigmoid() # cx,cy,w,h # 地平线参考算法 class MapInstanceDetectorHead(nn.Module): ... def get_outputs(...): ... for lvl in range(len(outputs_classes)): tmp = reference_out[lvl].float() outputs_coord, outputs_pts_coord = self.transform_box(tmp) outputs_class = outputs_classes[lvl].float() outputs_classes_one2one.append( outputs_class[:, 0 : self.num_vec_one2one] ) outputs_coords_one2one.append( outputs_coord[:, 0 : self.num_vec_one2one] ) outputs_pts_coords_one2one.append( outputs_pts_coord[:, 0 : self.num_vec_one2one] ) outputs_classes_one2many.append( outputs_class[:, self.num_vec_one2one :] ) outputs_coords_one2many.append( outputs_coord[:, self.num_vec_one2one :] ) outputs_pts_coords_one2many.append( outputs_pts_coord[:, self.num_vec_one2one :] ) ... def forward(...): outputs = self.bev_decoder(...) if self.is_deploy: return outputs ... outputs = self.get_outputs(...) ... return self._post_process(data, outputs)
5.Attention 结构优化,通过数值融合方法,将部分数值运算提前进行融合,减少整体的量化操作,提高模型的量化友好度
4.4 其他优化
4.4.1 设计优化
五、总结与建议
5.1 部署建议
5.2 总结
本文通过对 MapTR 进行地平线量化部署的优化,使得模型在征程 6 计算平台上用较低的量化精度损失,最优获得征程 6M 单核 93.77 FPS 的部署性能。同时,MapTR 系列的部署经验可以推广到其他相似结构或相似使用场景模型的部署中。
对于地平线 MapTR 参考算法模型,结合 Sparse Bev 等的优化方向仍在探索和实践中,Stay Tuned!
六、附录
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
