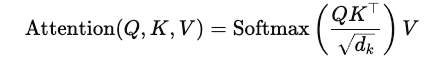在当今大模型蓬勃发展的时代,训练效率成为了制约模型发展与应用的关键因素。Transformer 架构中的自注意力机制虽强大,但面临着高计算成本与内存消耗的挑战。FlashAttention 应运而生,作为一种高效的注意力计算方法,它在加速模型训练与减少内存占用方面展现出了卓越的性能,为大模型的发展注入了新的活力。本文将深入探讨 FlashAttention 的原理,并结合代码实例进行详细解析。FlashAttention 是一种专为 Transformer 优化的高性能注意力机制。它能显著加速训练和推理,同时减少内存占用,广泛应用于 LLaMA、GPT-NeoX、PaLM 等大模型中。
一、Transformer 中的自注意力机制痛点
在深入了解 FlashAttention 之前,我们先来回顾一下 Transformer 中自注意力机制的标准计算过程。自注意力机制在 Transformer 架构中占据核心地位,它能够让模型在处理序列数据时,关注序列中不同位置的信息,从而更好地捕捉长距离依赖关系。
Transformer 的核心操作是自注意力(Self-Attention):
Transformer 的自注意力机制虽然强大,但其性能限制严重影响大模型的训练和推理速度,主要包括计算复杂度、显存开销和硬件利用率低这三个方面。然而,它存在两个关键问题:
计算复杂度高:标准 Attention 是O(N2)O(N2)时间复杂度和O(N2)O(N2)空间复杂度(N 为序列长度)。
内存****访问效率低:实际计算中频繁进行中间结果读写,造成大量 GPU memory bandwidth 消耗。
**算力****利用率低:**Attention 的中间结果频繁写入全局内存(global memory),不仅慢,还会造成 “算力利用率低”。
所以,FlashAttention 的目标是最小化显存读写,最大化 shared memory 和 register 利用率。
二、FlashAttention 的核心原理与优化策略
FlashAttention 的设计基于 IO - Awareness 理念,即通过优化算法,使其适应现代 GPU 的实际内存层次结构。在现代 GPU 中,内存通常分为高带宽内存(HBM)和片上静态随机存取存储器(SRAM)。HBM 具有较大的内存容量,但访问速度相对较慢;SRAM 虽然容量较小,但访问速度极快。
FlashAttention 通过精心设计的算法,尽可能地减少 HBM 与 SRAM 之间的数据传输次数,充分利用 SRAM 的高速访问特性,将更多的计算任务放在 SRAM 中完成,从而降低了内存访问成本,提高了计算效率。
FlashAttention 是一种内存****访问优化 + 精度保障 + CUDA kernel 融合的注意力计算方法,其目标是:
不牺牲精度(与原始 Attention 完全一致)
Fast:能够显著加快模型训练的速度。通过优化计算流程,减少不必要的内存访问和计算步骤,使得在相同的硬件条件下,模型的训练时间得以大幅缩短。
Memory - Efficient:实现内存高效,可有效减少显存的占用。这一特性对于处理大规模数据和复杂模型结构至关重要,能够让模型在有限的硬件资源下运行更大规模的训练任务。
并且,FlashAttention 保证了 exact attention,即它和标准的 attention 计算得到的结果是完全一致的,并不像其他一些算法是以降低 attention 的精度为代价来提高训练速度的。
核心思想:将 Attention 的计算流程重写为流式块状计算(tiling)并结合数值稳定的 softmax 分段求解。
2.1 流式块状计算
FlashAttention 采用分块计算(Tiling)的策略来优化计算过程。具体来说,它将输入的矩阵Q、K、V划分成多个小块(tiles),然后逐块进行处理。
思路:
将整个序列划分为小块(tiles),比如 64 × 64 或 128 × 128。
每次只加载一个 block 的Qi,Kj,VjQi,Kj,Vj到 shared memory 中,局部计算,再释放。
序列分块: Q = [Q1][Q2]...[Qm] K/V = [K1][K2]...[Kn]
FlashAttention 计算流程:
┌────K1────┐ ┌────K2────┐ ┌────K3────┐ ...
Q1 --> │Q1•K1^T │→│Q1•K2^T │→│Q1•K3^T │→ ...
└────┬─────┘ └────┬─────┘ └────┬─────┘
↓ ↓ ↓
Softmax Softmax Softmax (带最大值平移)
↓ ↓ ↓
O1+=V1 O1+=V2 O1+=V3 (累积求和)
从 global memory 加载QiQi和Kj,VjKj,Vj到 shared memory
局部计算QiKjTQiKjT→ 得到 attention logits
局部执行 Softmax(使用分段累积技巧)
与VjVj相乘累加结果 → 更新OiOi
2.2 分段数值稳定 Softmax
如果直接分段计算(tile-wise)容易数值不稳定。
FlashAttention 解法:
FlashAttention 引入了 段间合并策略,每个 tile 都维护。使用 log-sum-exp trick 做稳定计算:
# 每块 tile_j 的局部最大值和 sum
m_j = max(qk_tile_j)
s_j = sum(exp(qk_tile_j - m_j))
# 合并新块 j 与已有的 m, s
m_new = max(m, m_j)
s_new = exp(m - m_new) * s + exp(m_j - m_new) * s_j
每次更新 m 和 s,用稳定的递归方式合并 softmax,最终:
这种分段 Softmax 能保证输出数值与全局 Softmax 完全一致!
2.3 Fused kernel 实现(避免 kernel launch 开销)
FlashAttention 使用自定义 CUDA kernel 将以下步骤融合为一个 kernel:
[Q, K, V] → compute QK^T → softmax → weighted sum with V → Output
所有中间计算 全部保存在 register / shared memory
充分利用 Tensor Core 和 warp-level primitives(如 warp shuffle)
三、PyTorch 示例:普通 Attention vs FlashAttention
我们以一个 HuggingFace 模型中 Attention 层为例,先看原始实现:
# 标准注意力
attn_scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)
attn_weights = F.softmax(attn_scores, dim=-1)
output = torch.matmul(attn_weights, v)
替换为 FlashAttention(以 flash-attn 库为例):
from flash_attn import flash_attn_func
# 输入格式:[batch_size, seq_len, num_heads, head_dim]
qkv = torch.stack([q, k, v], dim=2) # 合并为 (B, L, 3, H, D)
output = flash_attn_func(qkv, causal=False)
四、FlashAttention CUDA 内核机制
全部在 CUDA kernel 内完成 softmax + matmul + 累加,无需中间写入 global memory
基于 Warp-tiling 和 Tensor Core 优化矩阵乘法
使用 fused kernel 避免 kernel launch 开销
FlashAttention 的 CUDA 核心结构如下(伪代码):
__global__ void flash_attention_kernel(Q, K, V, O) {
// Tile Q, K, V 到 shared memory
for (block in sequence) {
float max = -inf;
float sum = 0;
for (tile_j in K tiles) {
qk = dot(Q_block, K_tile_j);
max = max(max, max(qk));
sum += exp(qk - max);
acc += exp(qk - max) * V_tile_j;
}
O_block = acc / sum;
}
}所有计算完成前仅用 register / shared memory,不访问 global memory
充分使用 GPU Tensor Core、Warp Shuffle 等硬件特性
五、参考链接
https://github.com/Dao-AILab/flash-attention/blob/main/csrc/flash_attn/flash_api.cpp
https://github.com/DL-Attention/flash-attention-1?utm_source=chatgpt.com
五、参考链接
https://github.com/Dao-AILab/flash-attention/blob/main/csrc/flash_attn/flash_api.cpp
https://github.com/DL-Attention/flash-attention-1?utm_source=chatgpt.com
https://blog.csdn.net/weixin_41645791/article/details/148125854
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。