AMD 利用有史以来最先进的量产技术打造了 MI300 系列产品,采用 "3.5D "封装等新技术生产出两款多芯片巨型处理器,并称可在各种 AI 工作负载中提供与 Nvidia 不相上下的性能。其中有多项性能指标评测数倍于竞争对手英伟达的H100。AMD 没有透露其新的奇特芯片的价格,但这些产品现已向众多 OEM 合作伙伴发货。

Instinct MI300 是一种改变游戏规则的设计 - 数据中心 APU 混合了总共 13 个小芯片,其中许多是 3D 堆叠的,以创建一个具有 24 个 Zen 4 CPU 内核并融合了 CDNA 3 图形引擎和 8 个堆栈的芯片HBM3。总体而言,该芯片拥有 1530 亿个晶体管,是 AMD 迄今为止制造的最大芯片。AMD 声称该芯片在某些工作负载中的性能比 Nvidia H100 GPU 高出 4 倍,并宣称其每瓦性能是其两倍。
AMD 表示,其 Instinct MI300X GPU 在人工智能推理工作负载中的性能比 Nidia H100 高出 1.6 倍,并在训练工作中提供类似的性能,从而为业界提供了急需的 Nvidia GPU 的高性能替代品。此外,这些加速器的 HBM3 内存容量是 Nvidia GPU的两倍以上(每个 192 GB 令人难以置信),使其 MI300X 平台能够支持每个系统两倍以上的 LLM 数量,并运行比 Nvidia H100 HGX 更大的模型。
AMD Instinct MI300XMI300X代表了 AMD 基于小芯片的设计方法的顶峰,将八个 12Hi 堆栈的 HBM3 内存与八个 3D 堆栈的 5nm CDNA 3 GPU 小芯片(称为 XCD)融合在四个底层 6nm I/O 芯片上,这些芯片使用 AMD 现已成熟的技术进行连接混合键合技术。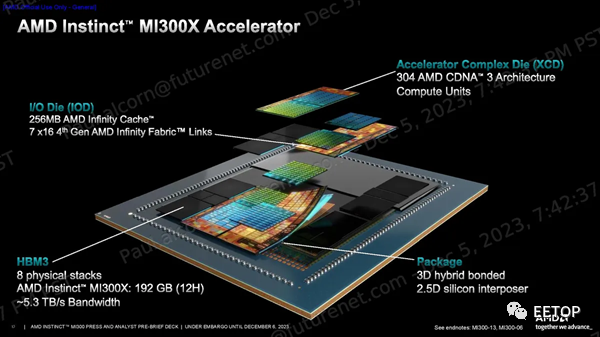





 结果是创造出了一个 750W 的加速器,拥有 304 个计算单元、192GB HBM3 容量和 5.3 TB/s 带宽。该加速器还具有 256MB Infinity Cache,用作共享 L3 缓存层,以促进小芯片之间的通信。AMD 将其将小芯片绑定在一起的封装技术称为“3.5D”,表示 3D 堆叠 GPU 和 I/O 芯片通过混合键合融合在一起,并与模块其余部分的标准 2.5D 封装(水平连接)相结合。。我们将更深入地研究下面的架构组件。
结果是创造出了一个 750W 的加速器,拥有 304 个计算单元、192GB HBM3 容量和 5.3 TB/s 带宽。该加速器还具有 256MB Infinity Cache,用作共享 L3 缓存层,以促进小芯片之间的通信。AMD 将其将小芯片绑定在一起的封装技术称为“3.5D”,表示 3D 堆叠 GPU 和 I/O 芯片通过混合键合融合在一起,并与模块其余部分的标准 2.5D 封装(水平连接)相结合。。我们将更深入地研究下面的架构组件。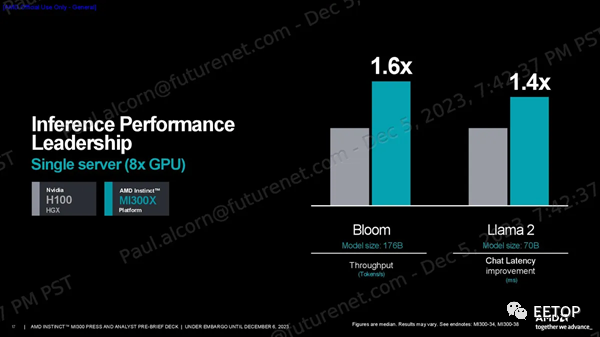
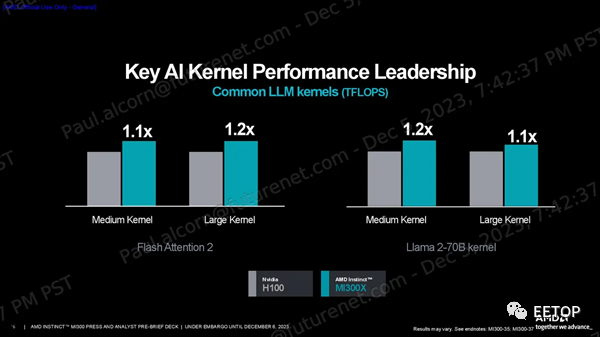


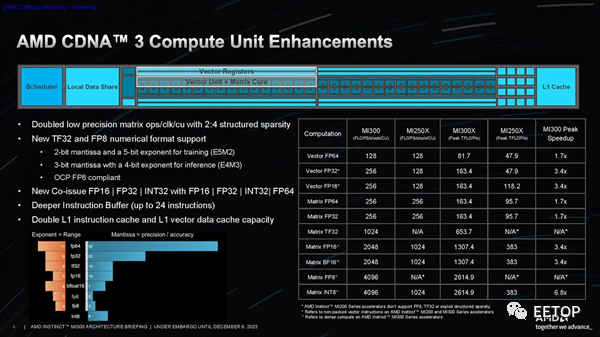
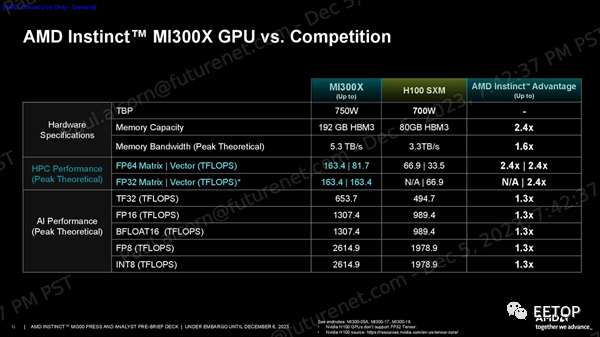 一如既往,我们应该谨慎对待供应商的基准测试。AMD 分享了一系列性能指标,显示其在 HPC 工作负载方面的 FP64 和 FP32 向量矩阵吞吐量峰值理论值是 H100 的 2.4 倍,在人工智能工作负载方面的 TF32、FP16、BF16、FP8 和 INT8 吞吐量峰值理论值是 H100 的 1.3 倍,所有这些都是在没有稀疏性的情况下预测的(不过 MI300X 确实支持稀疏性)。MI300X 的大内存容量和带宽非常适合推理。AMD 使用 1760 亿参数的 Flash Attention 2 模型声称在令牌/秒吞吐量方面比 Nvidia H100 具有 1.6 倍的性能优势,并使用 700 亿参数的 Llama 2 模型来强调 1.4 倍的聊天延迟优势(从2K 序列长度/128 个令牌工作负载的开始到结束)。
一如既往,我们应该谨慎对待供应商的基准测试。AMD 分享了一系列性能指标,显示其在 HPC 工作负载方面的 FP64 和 FP32 向量矩阵吞吐量峰值理论值是 H100 的 2.4 倍,在人工智能工作负载方面的 TF32、FP16、BF16、FP8 和 INT8 吞吐量峰值理论值是 H100 的 1.3 倍,所有这些都是在没有稀疏性的情况下预测的(不过 MI300X 确实支持稀疏性)。MI300X 的大内存容量和带宽非常适合推理。AMD 使用 1760 亿参数的 Flash Attention 2 模型声称在令牌/秒吞吐量方面比 Nvidia H100 具有 1.6 倍的性能优势,并使用 700 亿参数的 Llama 2 模型来强调 1.4 倍的聊天延迟优势(从2K 序列长度/128 个令牌工作负载的开始到结束)。


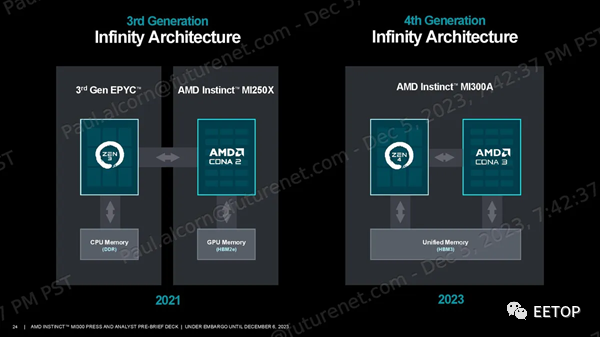

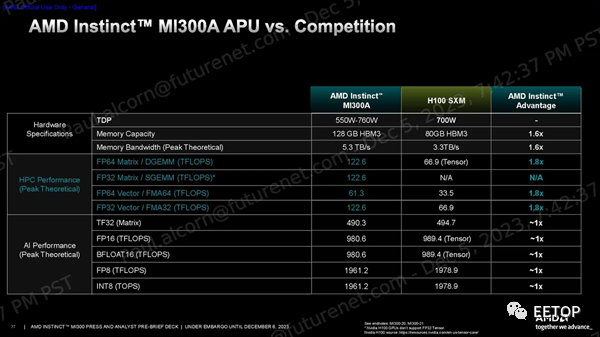 MI300A使用与 MI300X 相同的基本设计和方法,但替换为三个 5nm 核心计算芯片 (CCD),每个核心具有八个 Zen 4 CPU 核心,与 EPYC 和 Ryzen 处理器上的相同,从而取代了两个 XCD GPU 小芯片。这使得 MI300A 配备了 24 个线程 CPU 内核和分布在 6 个 XCD GPU 小芯片上的 228 个 CDNA 3 计算单元。与 MI300X 一样,所有计算小芯片均采用混合键合方式与四个底层 I/O 芯片 (IOD) 进行 3D 堆叠,以实现远超标准芯片封装技术所能实现的带宽、延迟和能源效率。AMD 压缩了内存容量,使用了 8 个 8Hi HBM3 堆栈,而不是 MI300X 使用的 8 个 12Hi 堆栈,因此容量从 192GB 降至 128GB。不过,内存带宽仍为 5.3 TB/s。AMD 告诉我们,减少内存容量的决定并不是因为功耗或散热限制;相反,这是为目标 HPC 和 AI 工作负载量身定制的芯片。无论如何,128GB 的容量和 5.3 TB/s 的吞吐量仍比 Nvidia 的 H100 SXM GPU 高出 1.6 倍。
MI300A使用与 MI300X 相同的基本设计和方法,但替换为三个 5nm 核心计算芯片 (CCD),每个核心具有八个 Zen 4 CPU 核心,与 EPYC 和 Ryzen 处理器上的相同,从而取代了两个 XCD GPU 小芯片。这使得 MI300A 配备了 24 个线程 CPU 内核和分布在 6 个 XCD GPU 小芯片上的 228 个 CDNA 3 计算单元。与 MI300X 一样,所有计算小芯片均采用混合键合方式与四个底层 I/O 芯片 (IOD) 进行 3D 堆叠,以实现远超标准芯片封装技术所能实现的带宽、延迟和能源效率。AMD 压缩了内存容量,使用了 8 个 8Hi HBM3 堆栈,而不是 MI300X 使用的 8 个 12Hi 堆栈,因此容量从 192GB 降至 128GB。不过,内存带宽仍为 5.3 TB/s。AMD 告诉我们,减少内存容量的决定并不是因为功耗或散热限制;相反,这是为目标 HPC 和 AI 工作负载量身定制的芯片。无论如何,128GB 的容量和 5.3 TB/s 的吞吐量仍比 Nvidia 的 H100 SXM GPU 高出 1.6 倍。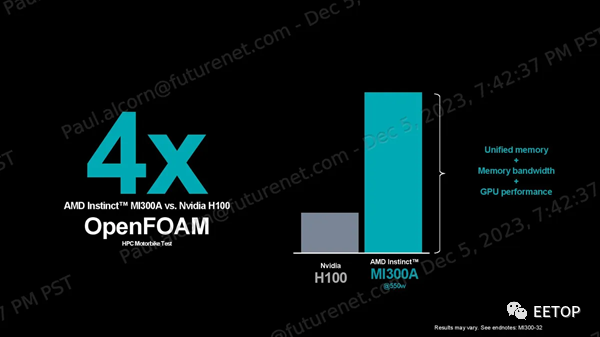
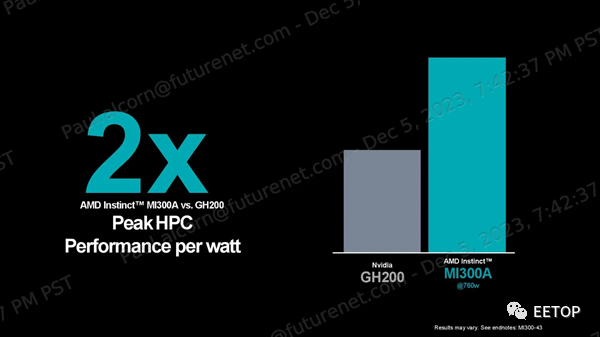
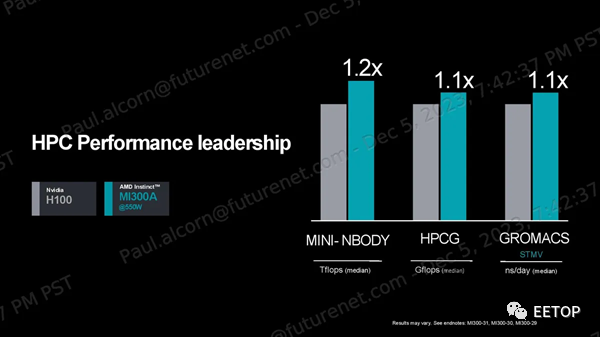 AMD声称,在 OpenFOAM HPC motorbike 测试中,其 MI300A 比 Nvidia 的 H100 快 4 倍,但这种比较并不理想: H100是GPU,而MI300A的CPU和GPU混合计算通过共享内存寻址空间,在这种内存密集型、有时是串行的工作负载中提供了固有优势。如果与 Nvidia Grace Hopper GH200 超级芯片进行比较,效果会更好,该芯片也是将 CPU 和 GPU 紧密耦合在一起实现的,但 AMD 表示无法找到 Nvidia GH200 的任何公开 OpenFOAM 结果。AMD 确实提供了与 Nvidia GH200 的每瓦性能比较数据,以强调 2 倍的优势,这些结果基于有关 H200 的公开信息。AMD 还强调了与 H100 在 Mini-Nbody、HPCG 和 Gromacs 基准测试中的比较,声称分别领先 1.2 倍、1.1 倍和 1.1 倍。同样,对于这组基准测试,与 GH200 进行比较会更理想。AMD Instinct MI300X 和 MI300A 架构我们介绍了上面设计的基础知识,这些细节为理解下面的部分提供了重要的视角。
AMD声称,在 OpenFOAM HPC motorbike 测试中,其 MI300A 比 Nvidia 的 H100 快 4 倍,但这种比较并不理想: H100是GPU,而MI300A的CPU和GPU混合计算通过共享内存寻址空间,在这种内存密集型、有时是串行的工作负载中提供了固有优势。如果与 Nvidia Grace Hopper GH200 超级芯片进行比较,效果会更好,该芯片也是将 CPU 和 GPU 紧密耦合在一起实现的,但 AMD 表示无法找到 Nvidia GH200 的任何公开 OpenFOAM 结果。AMD 确实提供了与 Nvidia GH200 的每瓦性能比较数据,以强调 2 倍的优势,这些结果基于有关 H200 的公开信息。AMD 还强调了与 H100 在 Mini-Nbody、HPCG 和 Gromacs 基准测试中的比较,声称分别领先 1.2 倍、1.1 倍和 1.1 倍。同样,对于这组基准测试,与 GH200 进行比较会更理想。AMD Instinct MI300X 和 MI300A 架构我们介绍了上面设计的基础知识,这些细节为理解下面的部分提供了重要的视角。


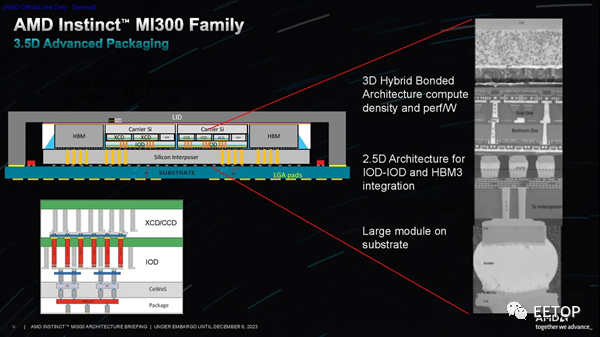
 AMD利用台积电的 3D 混合键合 SoIC(集成电路上硅)技术,在四个底层 I/O 芯片之上对各种计算元件进行 3D 堆叠,无论是 CPU CCD(核心计算芯片)还是 GPU XCD。每个 I/O 芯片可以容纳两个 XCD 或三个 CCD。每个 CCD 与现有 EPYC 芯片中使用的 CCD 相同,每个 CCD 拥有八个超线程 Zen 4 核心。MI300A 使用了其中的三个 CCD 和六个 XCD,而 MI300X 使用了八个 XCD。HBM 堆栈使用采用 2.5D 封装技术的标准中介层进行连接。AMD 将 2.5D 和 3D 封装技术相结合,使该公司创造了“3.5D”封装的绰号。每个 I/O 芯片都包含一个 32 通道 HBM3 内存控制器,用于托管 8 个 HBM 堆栈中的两个,从而为该设备提供了总共 128 个 16 位内存通道。MI300X 采用 12Hi HBM3 堆栈,容量为 192GB,而 MI300A 使用 8Hi 堆栈,容量为 128GB。AMD 还增加了 256MB 的无限缓存总容量,分布在所有四个 I/O 芯片上,通过预取器缓存数据流量,从而提高命中率和电源效率,同时减少总线争用和延迟。这为 CPU 增加了新级别的缓存(概念上是共享 L4),同时为 GPU 提供共享 L3 缓存。Infinity Fabric NoC(片上网络)被称为 AMD Infinity Fabric AP(高级封装)互连,用于连接 HBM、I/O 子系统和计算。该芯片总共具有 128 个 PCIe 5.0 连接通道,分布在四个 I/O 芯片上。它们被分为两组:一组是四个 x16 PCIe 5.0 + 第四代 Infinity Fabric 链路的组合,而另一组则有四个专门用于 Infinity Fabric 的 x16 链路。后者仅用于将 MI300 相互连接(跨套接字流量)。MI300X 纯粹用作端点设备 - 它连接到外部 CPU - 因此其 PCIe 根节点需要充当端点设备。相比之下,MI300A 由于其本机 CPU 内核而采用自托管,因此 PCIe 根联合体必须充当主机。为了适应这两种场景,AMD 定制的 MI300 I/O 裸片支持来自同一 PCIe 5.0 根节点的两种模式,该根节点是该公司 IP 产品组合的新成员。AMD 的 CPU CCD 通过 3D 混合键合到底层 I/O 芯片,需要新的接口。虽然这与 EPYC 服务器处理器中的 CCD 相同,但这些芯片通过利用标准 2.5D 封装的GMI3 (Global Memory Interconnect 3) 接口进行通信。对于 MI300,AMD 添加了一个新的焊盘通孔接口,可绕过 GMI3 链路,从而提供垂直堆叠芯片所需的 TSV(通过硅通孔)。该接口在双链路宽模式下运行。
AMD利用台积电的 3D 混合键合 SoIC(集成电路上硅)技术,在四个底层 I/O 芯片之上对各种计算元件进行 3D 堆叠,无论是 CPU CCD(核心计算芯片)还是 GPU XCD。每个 I/O 芯片可以容纳两个 XCD 或三个 CCD。每个 CCD 与现有 EPYC 芯片中使用的 CCD 相同,每个 CCD 拥有八个超线程 Zen 4 核心。MI300A 使用了其中的三个 CCD 和六个 XCD,而 MI300X 使用了八个 XCD。HBM 堆栈使用采用 2.5D 封装技术的标准中介层进行连接。AMD 将 2.5D 和 3D 封装技术相结合,使该公司创造了“3.5D”封装的绰号。每个 I/O 芯片都包含一个 32 通道 HBM3 内存控制器,用于托管 8 个 HBM 堆栈中的两个,从而为该设备提供了总共 128 个 16 位内存通道。MI300X 采用 12Hi HBM3 堆栈,容量为 192GB,而 MI300A 使用 8Hi 堆栈,容量为 128GB。AMD 还增加了 256MB 的无限缓存总容量,分布在所有四个 I/O 芯片上,通过预取器缓存数据流量,从而提高命中率和电源效率,同时减少总线争用和延迟。这为 CPU 增加了新级别的缓存(概念上是共享 L4),同时为 GPU 提供共享 L3 缓存。Infinity Fabric NoC(片上网络)被称为 AMD Infinity Fabric AP(高级封装)互连,用于连接 HBM、I/O 子系统和计算。该芯片总共具有 128 个 PCIe 5.0 连接通道,分布在四个 I/O 芯片上。它们被分为两组:一组是四个 x16 PCIe 5.0 + 第四代 Infinity Fabric 链路的组合,而另一组则有四个专门用于 Infinity Fabric 的 x16 链路。后者仅用于将 MI300 相互连接(跨套接字流量)。MI300X 纯粹用作端点设备 - 它连接到外部 CPU - 因此其 PCIe 根节点需要充当端点设备。相比之下,MI300A 由于其本机 CPU 内核而采用自托管,因此 PCIe 根联合体必须充当主机。为了适应这两种场景,AMD 定制的 MI300 I/O 裸片支持来自同一 PCIe 5.0 根节点的两种模式,该根节点是该公司 IP 产品组合的新成员。AMD 的 CPU CCD 通过 3D 混合键合到底层 I/O 芯片,需要新的接口。虽然这与 EPYC 服务器处理器中的 CCD 相同,但这些芯片通过利用标准 2.5D 封装的GMI3 (Global Memory Interconnect 3) 接口进行通信。对于 MI300,AMD 添加了一个新的焊盘通孔接口,可绕过 GMI3 链路,从而提供垂直堆叠芯片所需的 TSV(通过硅通孔)。该接口在双链路宽模式下运行。

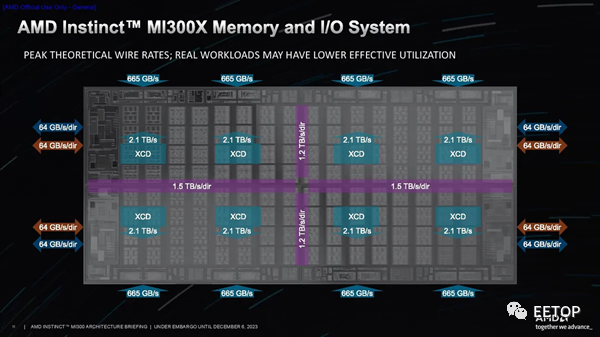
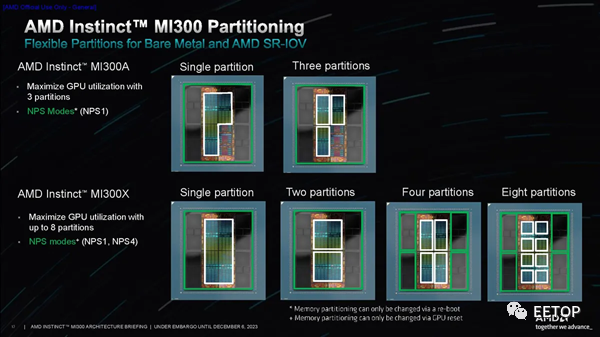 每个 I/O 裸片上连接有两个 XCD,然后连接到两个 HBM3 堆栈。这样,GPU 就能与两个连接的堆栈进行私密通信,以缓解带宽、延迟和一致性问题。不过,每个 XCD 都可以与任何内存堆栈通信(I/O 裸片之间的 Infinity Fabric 连接在PPT的前两张图片中以彩色条形直观显示)。当然,寻址远程堆栈会带来延迟损失。内存事务传输得越远,就会产生越长的延迟。AMD 指出,直接连接到 IOD 和 XCD 的 HBM 是零跳事务(zero-hop),而访问 IOD 上的不同内存堆栈则需要两跳。最后,访问相邻 IOD 上的内存堆栈是三跳跳转。两跳跳转的延迟大约增加 30%,而三跳跳转的延迟则增加 60%。第三张PPT显示了 NoC 提供的带宽,在整个封装的垂直部分,I/O Dies 之间的带宽为 1.2 TB/s/dir,而水平数据路径提供的带宽略高,为 1.5 TB/s/dir,以帮助容纳来自 I/O 设备的额外流量,从而允许 I/O 流量与内存流量分开处理。封装右侧和左侧的 PCIe可从每个 I/O 芯片提供 64 GB/s/dir 的吞吐量。在封装的顶部和底部,可以看到每个 HBM 堆栈提供 665 GB/s 的吞吐量。AMD 有多种分区方案,可将计算单元划分为不同的逻辑域,就像 EPYC 处理器的 NPS 设置一样。这允许将不同的 XCD 分成不同的组以优化带宽,从而最大限度地提高性能并限制“NUMAness”的影响。多种配置范围从将单元寻址为一个逻辑设备到将它们寻址为八个不同的设备,以及多种中间选项,为各种工作负载提供了足够的灵活性。
每个 I/O 裸片上连接有两个 XCD,然后连接到两个 HBM3 堆栈。这样,GPU 就能与两个连接的堆栈进行私密通信,以缓解带宽、延迟和一致性问题。不过,每个 XCD 都可以与任何内存堆栈通信(I/O 裸片之间的 Infinity Fabric 连接在PPT的前两张图片中以彩色条形直观显示)。当然,寻址远程堆栈会带来延迟损失。内存事务传输得越远,就会产生越长的延迟。AMD 指出,直接连接到 IOD 和 XCD 的 HBM 是零跳事务(zero-hop),而访问 IOD 上的不同内存堆栈则需要两跳。最后,访问相邻 IOD 上的内存堆栈是三跳跳转。两跳跳转的延迟大约增加 30%,而三跳跳转的延迟则增加 60%。第三张PPT显示了 NoC 提供的带宽,在整个封装的垂直部分,I/O Dies 之间的带宽为 1.2 TB/s/dir,而水平数据路径提供的带宽略高,为 1.5 TB/s/dir,以帮助容纳来自 I/O 设备的额外流量,从而允许 I/O 流量与内存流量分开处理。封装右侧和左侧的 PCIe可从每个 I/O 芯片提供 64 GB/s/dir 的吞吐量。在封装的顶部和底部,可以看到每个 HBM 堆栈提供 665 GB/s 的吞吐量。AMD 有多种分区方案,可将计算单元划分为不同的逻辑域,就像 EPYC 处理器的 NPS 设置一样。这允许将不同的 XCD 分成不同的组以优化带宽,从而最大限度地提高性能并限制“NUMAness”的影响。多种配置范围从将单元寻址为一个逻辑设备到将它们寻址为八个不同的设备,以及多种中间选项,为各种工作负载提供了足够的灵活性。 
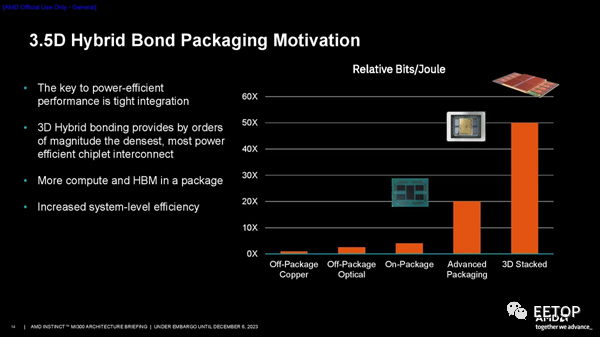
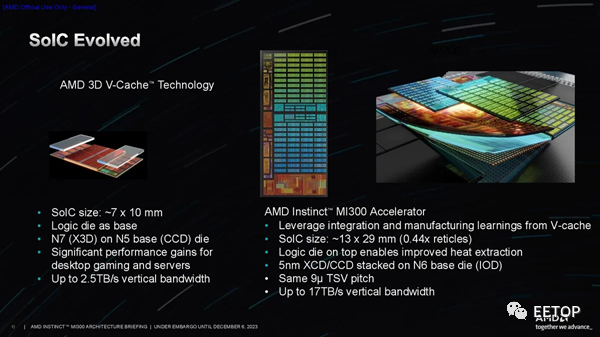
 AMD确定 3D 混合键合 (SoIC) 是在计算单元和 I/O 芯片之间提供足够带宽的唯一现实途径。公司在该技术方面拥有丰富的经验;它已经应用于数百万个配备 3D V-Cache的 PC 处理器中。
AMD确定 3D 混合键合 (SoIC) 是在计算单元和 I/O 芯片之间提供足够带宽的唯一现实途径。公司在该技术方面拥有丰富的经验;它已经应用于数百万个配备 3D V-Cache的 PC 处理器中。 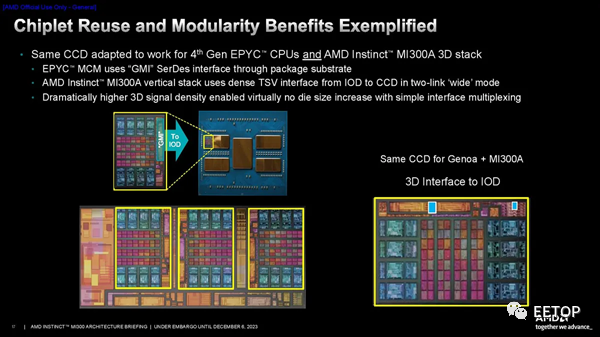

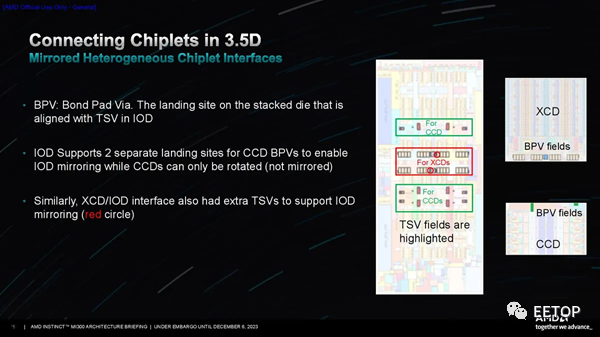

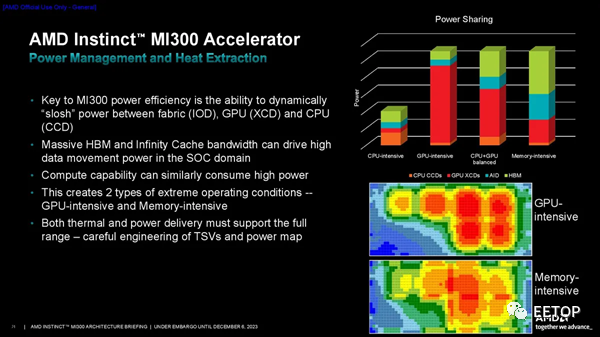 AMD高级副总裁、AMD 公司院士兼产品技术架构师 Sam Naffziger介绍了团队在设计阶段遇到的一些挑战。巧妙的IP重用一直是AMD小芯片战略的基石,MI300也不例外。MI300 团队没有资源为 MI300 构建全新的 CPU CCD,因此他们要求该公司的 CCD 团队在设计阶段的早期将 3D 接口 (TSV) 添加到 EPYC CCD。令人惊讶的是,工程团队找到了一种将连接塞入现有 GMI 接口之间的方法。 在第一张幻灯片中,您可以看到两个小蓝点代表 TSV 的总面积,而点两侧的大橙色矩形块是用于 2.5D 封装的标准 GMI3 接口。这说明了 SoIC 技术的密度和面积效率是多么令人难以置信。AMD 还添加了一些门、开关和多路复用器,以允许信号从 GMI3 接口重新路由到 3D 接口。AMD创建了 I/O Die的镜像版本,以确保它们可以旋转到正确的位置,同时确保 XCD 中的内存控制器和其他接口仍然正确对齐。工程团队对称地设计了接口/信号和电源连接,从而允许小芯片旋转,如第二张图所示。然而,虽然 AMD 专门为 MI300 从头开始设计了 I/O Die,但该团队必须采用 EPYC 的现有 CCD 设计。他们不想为 CCD 创建镜面掩模组,这在此类设计中通常是必需的,以确保正确的接口对齐,因为这会增加设计的成本和复杂性。然而,其中两个 CCD 需要旋转 180 度才能确保正确对齐。然而,CCD的外部接口设计不对称,因此带来了挑战。如第三张幻灯片所示,AMD 通过在 I/O Die上的键合焊盘通孔 (BPV) 连接点添加一些冗余来克服这一挑战,从而允许 CCD 仅旋转而不是镜像。不过,供电输送仍然是一个挑战。TSV 是非常小的铜插头,AMD 需要为位于 I/O Die顶部的计算芯片提供数百安培的电源。细小的 TSV 不太适合这项工作,因此它们需要大量的连接来供电。AMD 设计了一种新的电网来克服这个问题,它满足了 IR 压降目标,并且没有超过电流密度限制。 最后,由于 3D 堆叠设计,该设计提出了一些新的热挑战。通过热建模,AMD 确定了两种类型的极端操作条件 - 内存密集型和 GPU 密集型 - 然后利用其基于使用模式在单元之间动态转移功率的行之有效的策略来帮助缓解这些问题。 因此,一个令人难以置信的处理器诞生了。AMD的MI300在相当长的一段时间内对Nvidia在AI和HPC工作负载方面的性能主导地位提出了第一次真正的挑战,AMD坚称自己有能力满足需求。在 GPU 短缺的时代,这是一种竞争优势,并且肯定会刺激行业的快速发展。AMD 现在正在向其合作伙伴运送 MI300 处理器。
AMD高级副总裁、AMD 公司院士兼产品技术架构师 Sam Naffziger介绍了团队在设计阶段遇到的一些挑战。巧妙的IP重用一直是AMD小芯片战略的基石,MI300也不例外。MI300 团队没有资源为 MI300 构建全新的 CPU CCD,因此他们要求该公司的 CCD 团队在设计阶段的早期将 3D 接口 (TSV) 添加到 EPYC CCD。令人惊讶的是,工程团队找到了一种将连接塞入现有 GMI 接口之间的方法。 在第一张幻灯片中,您可以看到两个小蓝点代表 TSV 的总面积,而点两侧的大橙色矩形块是用于 2.5D 封装的标准 GMI3 接口。这说明了 SoIC 技术的密度和面积效率是多么令人难以置信。AMD 还添加了一些门、开关和多路复用器,以允许信号从 GMI3 接口重新路由到 3D 接口。AMD创建了 I/O Die的镜像版本,以确保它们可以旋转到正确的位置,同时确保 XCD 中的内存控制器和其他接口仍然正确对齐。工程团队对称地设计了接口/信号和电源连接,从而允许小芯片旋转,如第二张图所示。然而,虽然 AMD 专门为 MI300 从头开始设计了 I/O Die,但该团队必须采用 EPYC 的现有 CCD 设计。他们不想为 CCD 创建镜面掩模组,这在此类设计中通常是必需的,以确保正确的接口对齐,因为这会增加设计的成本和复杂性。然而,其中两个 CCD 需要旋转 180 度才能确保正确对齐。然而,CCD的外部接口设计不对称,因此带来了挑战。如第三张幻灯片所示,AMD 通过在 I/O Die上的键合焊盘通孔 (BPV) 连接点添加一些冗余来克服这一挑战,从而允许 CCD 仅旋转而不是镜像。不过,供电输送仍然是一个挑战。TSV 是非常小的铜插头,AMD 需要为位于 I/O Die顶部的计算芯片提供数百安培的电源。细小的 TSV 不太适合这项工作,因此它们需要大量的连接来供电。AMD 设计了一种新的电网来克服这个问题,它满足了 IR 压降目标,并且没有超过电流密度限制。 最后,由于 3D 堆叠设计,该设计提出了一些新的热挑战。通过热建模,AMD 确定了两种类型的极端操作条件 - 内存密集型和 GPU 密集型 - 然后利用其基于使用模式在单元之间动态转移功率的行之有效的策略来帮助缓解这些问题。 因此,一个令人难以置信的处理器诞生了。AMD的MI300在相当长的一段时间内对Nvidia在AI和HPC工作负载方面的性能主导地位提出了第一次真正的挑战,AMD坚称自己有能力满足需求。在 GPU 短缺的时代,这是一种竞争优势,并且肯定会刺激行业的快速发展。AMD 现在正在向其合作伙伴运送 MI300 处理器。*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

