在【LLM】LLM 中增量解码与模型推理解读一文中对 LLM 常见名词进行了介绍,本文会对 LLM 中评价指标与训练概要进行介绍,本文并未介绍训练实操细节,未来有机会再了解~
一、LLM 如何停止输出
在看 LLM 评价指标前,先看看 LLM 如何停止输出。
模型生成特殊终止符(如 DeepSeek R1 MoE 中 ID 为 1 的 token)表示回答完成。
最大长度限制 预设生成 token 上限(常见值:512/1024/2048),防止无限生成,保障系统资源安全。
停止词 / 序列触发 设置 “\n\n”“###” 等符号为停止信号,强制结束生成(适用于格式控制)。
内容智能判断
重复检测:识别循环或冗余内容时自动终止。
语义完整性:当回答覆盖查询所有维度(如时间、影响)时停止。
停止机制建议组合使用(如 EOS + 最大长度),确保生成既完整又可控。
综合来看,Decode 阶段的循环机制是大模型实现长文本生成的核心:
效率优化:通过 KV 缓存复用大幅降低计算成本;
可控生成:多维度停止策略平衡输出质量与资源消耗;
语义连贯:自回归模式确保上下文逻辑衔接紧密。
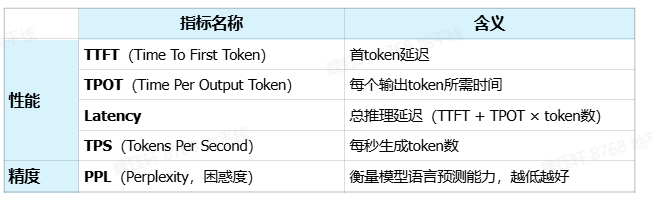
二、LLM 评价指标
三、LLM 训练概要
本节主要参考: https://zhuanlan.zhihu.com/p/719730442 https://zhuanlan.zhihu.com/p/1912101103086043526
数据准备:喂给模型“知识”
收集数据:从互联网、书籍、论文等获取海量文本(如英文维基百科+书籍+网页)。
清洗数据:过滤垃圾、重复内容、有害信息,保留高质量文本。
分词(Tokenization):把文本拆成“词语片段”(如用 Byte-Pair Encoding 或 SentencePiece)。
模型设计:搭建“大脑”结构
预训练(Pre-training):自主学习语言规律
微调(Fine-tuning):定向优化能力 场景化训练:用特定任务的数据(如客服对话、医疗问答)进一步优化模型。
评估与部署:测试和落地
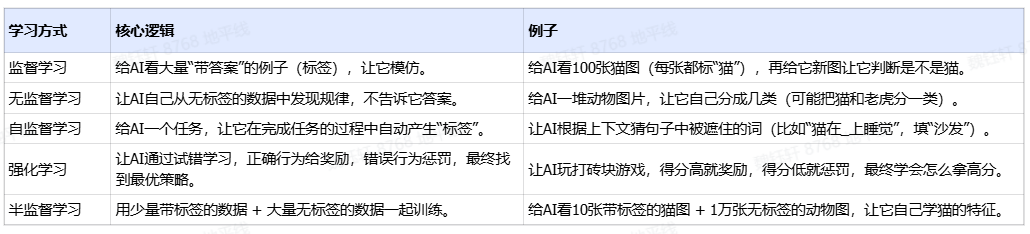
四、LLM 中学习策略
在上面的训练过程中,提到了“自监督学习"、"强化学习”这几个概念。这些都属于大模型训练过程中的学习策略或者叫学习范式,以下是对不同学习策略的总结和对比:
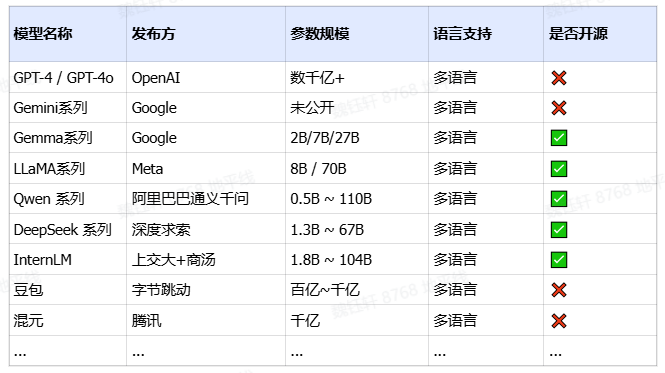
五、常见 LLM 模型
六、LLM 的挑战与展望
6.1 挑战
6.2 展望
近年来也发展出支持图像、语音、视频等多模态输入的 VLM(Vision-Language Models)和 VLA(Vision-Language-Action),可以研究学习的地方非常多。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。