在模型开发与应用领域,精准的性能分析和优化是提升效率的核心。地平线通过 征程 6 算法工具链 OE3.2.0 版本,对 hbm_perf 接口进行了重大升级,新增了 内存****占用信息 和 硬件占用 Timeline 两大功能 。这些强化功能使开发者能够清晰掌握模型运行时的资源消耗和硬件效率,为后续优化提供关键依据。本文将深入解读新版 perf 文件的核心内容,并结合实例分析性能优化策略。
二、新功能介绍2.1 内存占用信息新版 perf HTML 主页新增了模型运行时的内存占用详情,涵盖以下关键维度:
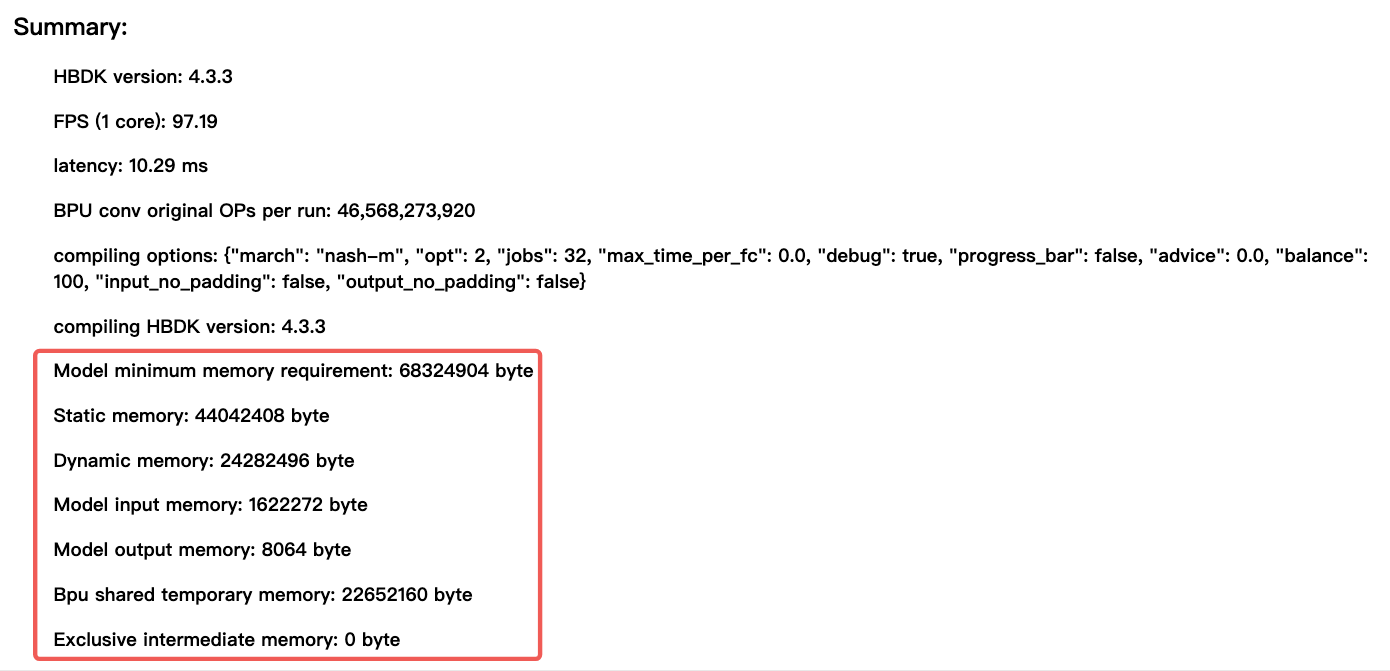
主要包括以下部分:
input **memory :**模型输入数据的内存占用,反映接收输入所需的空间大小。
output **memory:**模型输出结果的内存占用,直接影响结果生成效率。
Bpu **shared temporary memory & Exclusive intermediate memory:**运行时内存
**dynamic memory:前四项内存之和,代表动态资源需求,**即上图中 1622272+8064+22652160+0=24282496
**static memory:**hbm 文件大小
Model minimum memory requirement: dynamic memory+static memory
新增的 Timeline 功能通过时间序列图展示硬件操作耗时,横轴为时间(微秒),纵轴为操作类型(如 AAE、VAE、STORE 等)。关键应用包括:
TAE:张量加速单元,主要做 conv、matmu 计算;
VAE:向量加速单元,主要做逐点相加/乘计算;
AAE:偏专用单元的集合,包括 Pooling、Resizer、Warping 等;
Trans:数据搬运操作,包括 transpose、reshape 等;
LOAD/STORE:加载/存储数据;
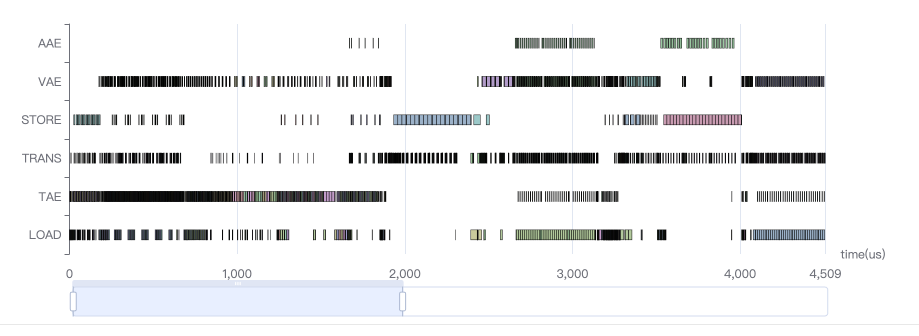
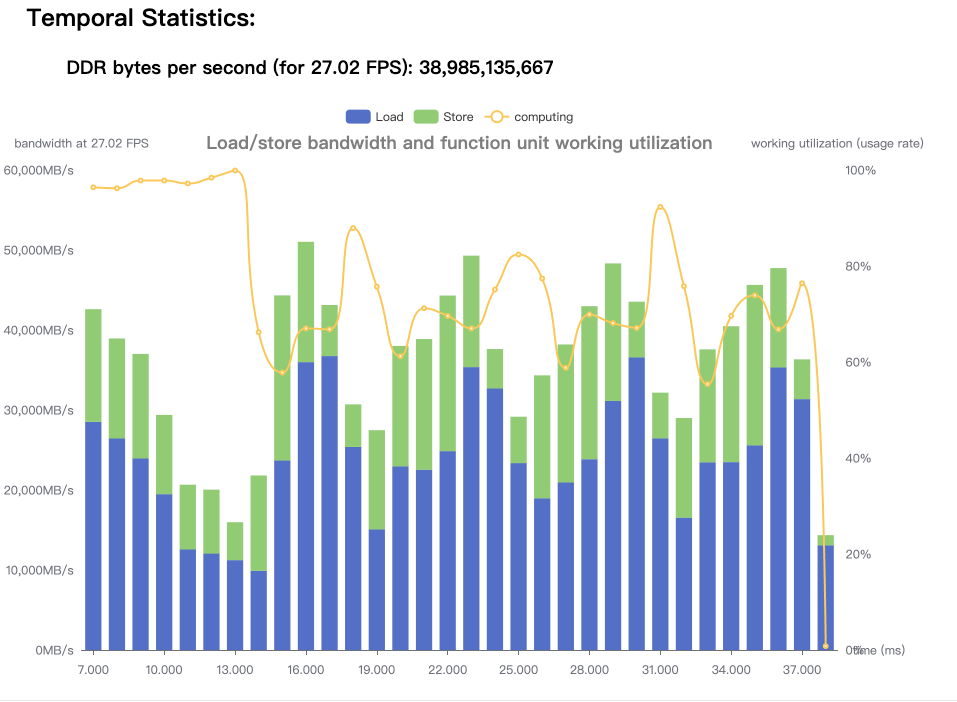
从上图看到,存在黄色的计算时间曲线低于 Load+Store 曲线的情况,所以模型中说存在带宽占用较高的算子的。
那么,如何查看这些算子呢?
3.2 查看占用时间较高的算子hbm_perf 的产出物中包括了 json 文件,我们可以使用这个 json 文件对性能做进一步的分析,比如每类算子的耗时,Top 耗时的算子,预计统计模型中每一部分耗时的算子。
3.2.1 每类算子耗时如下图是使用脚本统计的算子耗时,可以看到以下信息:
耗时比较高的是 Matmul 和 conv 算子;
matmul 算子引起了带宽瓶颈,即 ddr 耗时(load+store)大大超过了计算耗时;
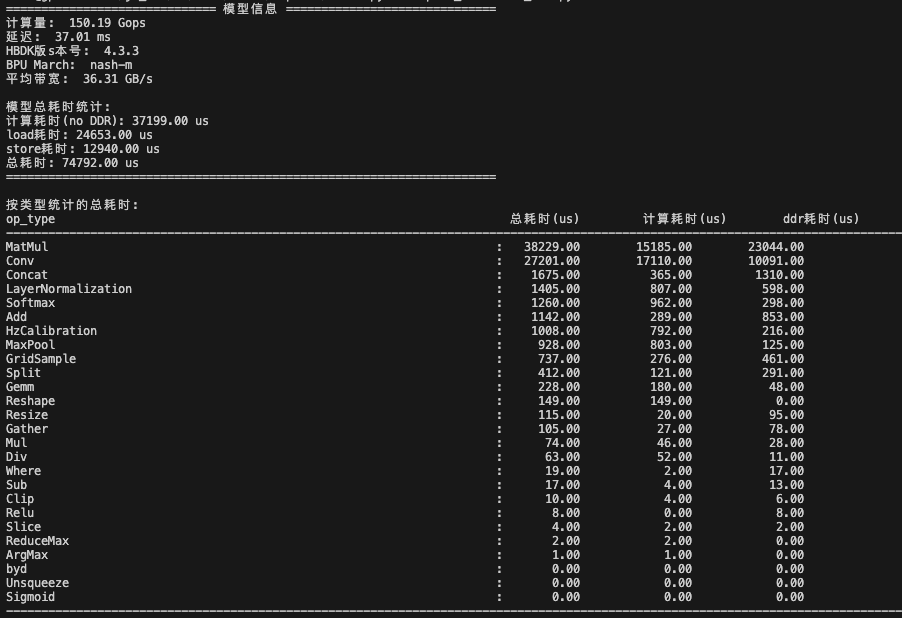
下面我们就着重看模型中的 matmul 算子。
3.2.2 Top 20 算子耗时在 perf.jso 的统计脚本中,增加了打印 Top 20 算子的耗时,即打印耗时最大的前 20 个算子,如下所示:

上图中,我们可以看到耗时最高的四个算子都是 Matmul 算子,此时我们需要结合 layername 到原始浮点 onnx/quantized.bc 中去查看这几个算子的属性。
这里以 MatMul2_id_1192 为例进行解析,原始浮点 onnx 的结构如下所示:
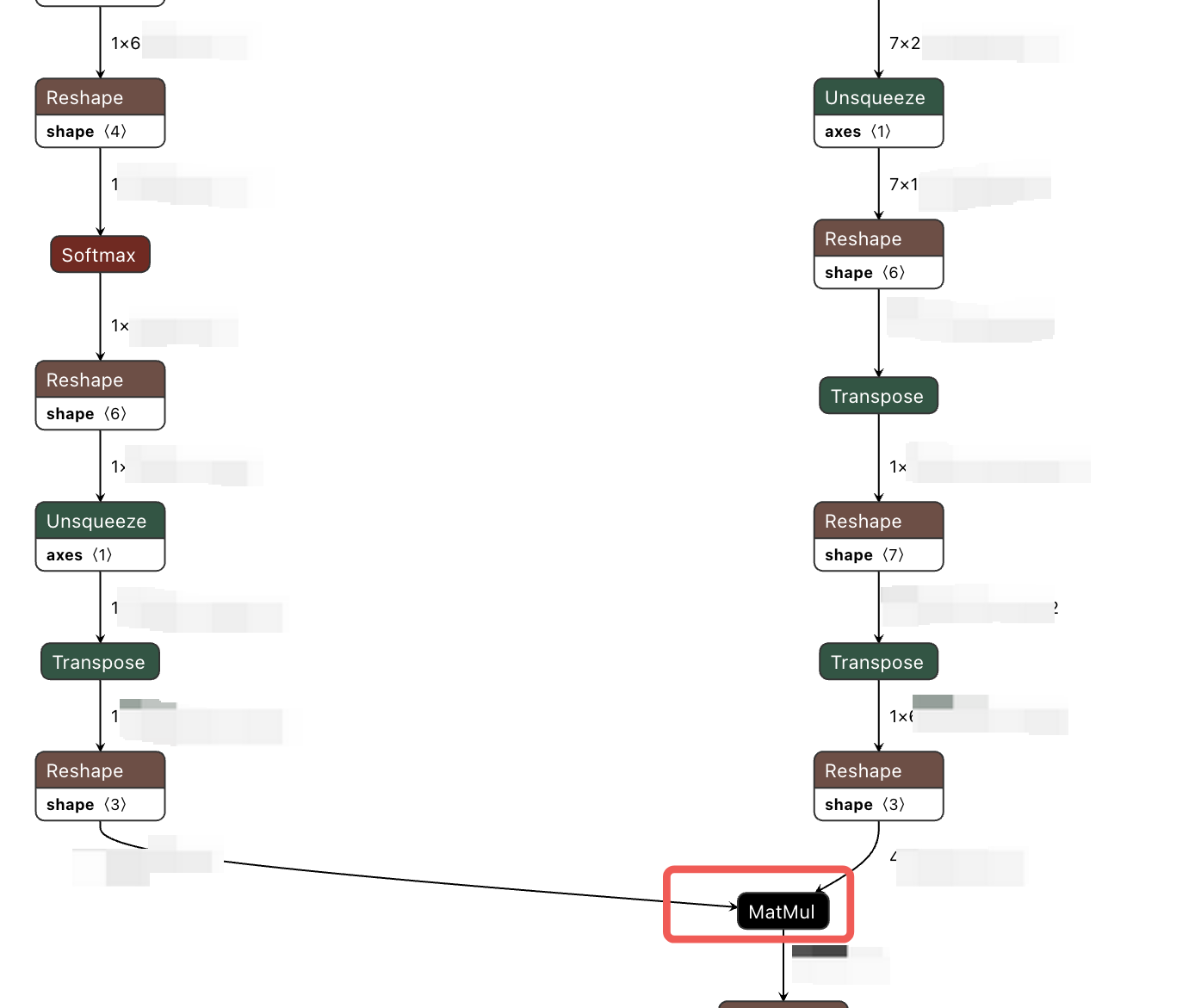 可以看到,这里 matmul 计算的前面有很多的数据搬运操作,这也是一个优化点,减少数据搬运操作可以显著降低带宽占用。
可以看到,这里 matmul 计算的前面有很多的数据搬运操作,这也是一个优化点,减少数据搬运操作可以显著降低带宽占用。
quantized.bc 可视化的结构如下:
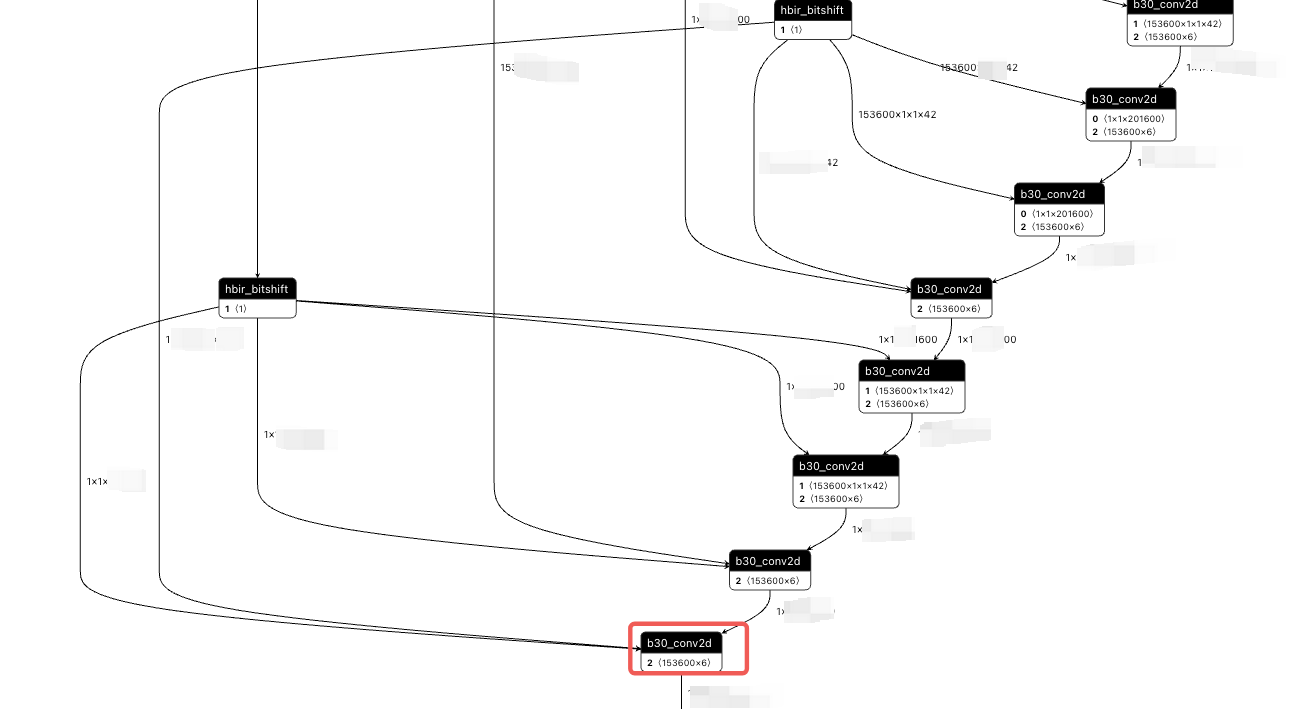
首先,可以看出这里的 matmul 计算是 int16 的,由于数据超出的硬件的限制,所以工具进行了自动拆分,但是由于数据了实在是太大了,所以这里的 matmul 的耗时还是非常高。
所以,这里有两点建议:
在实际部署中,matmul 并不一定需要 int16 精度,这里可以把 matmul 的输入/输出配置成 int8 量化;
如果 matmul 必须要保持 int16 量化精度,这里可以考虑将其等价替换为 mul+ReduceSum 计算;
附录中提供了统计算子耗时的脚本,输入为 perf.json 文件,输出为:
每种算子的总耗时、计算耗时和 ddr 耗时,有利于了解模型中算子的耗时分布和带宽占用;
耗时排名前 20 的算子,这些算子是耗时的瓶颈,需要针对性分析。
import json
import re
from collections import defaultdict
import time
import os
import sys
import logging
import csv
from collections import defaultdict
import sys
# ========== 配置日志 ==========
log_file = f"model.json"
logging.basicConfig(
level=logging.INFO,
format='%(message)s',
handlers=[
logging.FileHandler(log_file, mode='w', encoding='utf-8'),
logging.StreamHandler(sys.stdout)
]
)
def log(*args, **kwargs):
message = " ".join(str(arg) for arg in args)
logging.info(message)
# ========== 时间字符串解析 ==========
def parse_time(time_str):
if not time_str or time_str == '0':
return 0
if time_str.startswith("<"):
return 0
match = re.search(r'\d+', time_str)
if not match:
sys.exit("error: not find valid number!")
return float(match.group())
def analyze_and_save_layer_by_mod_qat(json_data, output_csv="layer_timing.csv"):
grouped_by_mod_prefix = defaultdict(list)
os.makedirs(output_csv,exist_ok=True)
for layer in json_data.get("layer details", []):
layer_name = layer.get("layer name", "")
computing_time = parse_time(layer.get("computing cost (no DDR)", "0"))
loading_time = parse_time(layer.get("load cost", "0"))
storeing_time = parse_time(layer.get("store cost", "0"))
total_time = computing_time + loading_time + storeing_time
# 提取 Mod 字段
mod_match = re.search(r'"Mod":\s*"([^"]+)"', layer_name)
if not mod_match:
mod_match=layer_name
mod_path=mod_match
else:
mod_path = mod_match.group(1)
mod_prefix = mod_path.split('.')[0] if '.' in mod_path else mod_path
grouped_by_mod_prefix[mod_prefix].append({
"mod_prefix": mod_prefix,
"mod_path": mod_path,
"total_time": total_time,
"compute": computing_time,
"load": loading_time,
"store": storeing_time
})
# 打印输出 + 按总耗时排序
# print("\n每个模块前缀下各算子详细耗时(按耗时降序):\n")
csv_rows = []
for mod_prefix, layers in grouped_by_mod_prefix.items():
sorted_layers = sorted(layers, key=lambda x: x["total_time"], reverse=True)
# print(f"模块: {mod_prefix} (共 {len(sorted_layers)} 层)")
# print("-" * 60)
for idx, layer in enumerate(sorted_layers, 1):
# print(f"{idx}. Layer: {layer['mod_path']}")
# print(f" 总耗时: {layer['total_time']:.2f} us")
# print(f" 计算: {layer['compute']:.2f} us | Load: {layer['load']:.2f} us | Store: {layer['store']:.2f} us")
csv_rows.append([
mod_prefix,
layer["mod_path"],
f"{layer['total_time']:.2f}",
f"{layer['compute']:.2f}",
f"{layer['load']:.2f}",
f"{layer['store']:.2f}"
])
# print("-" * 60)
# 保存为 CSV 文件
with open(output_csv, 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["mod_prefix", "mod_path", "total_time(us)", "compute(us)", "load(us)", "store(us)"])
writer.writerows(csv_rows)
print(f"\n✅ 每个 mod_prefix 内算子已按耗时降序排序,并保存到: {output_csv}")
from collections import defaultdict
import csv
import re
import os
from collections import defaultdict
def analyze_selected_mod_prefixes(json_data, selected_prefixes=None, csv_output_dir='./'):
os.makedirs(csv_output_dir, exist_ok=True)
grouped_by_custom_prefix = defaultdict(list)
for layer in json_data.get("layer details", []):
layer_name = layer.get("layer name", "")
computing_time = parse_time(layer.get("computing cost (no DDR)", "0"))
loading_time = parse_time(layer.get("load cost", "0"))
storeing_time = parse_time(layer.get("store cost", "0"))
total_time = computing_time + loading_time + storeing_time
if selected_prefixes:
for prefix in selected_prefixes:
if layer_name.strip().startswith(prefix):
grouped_by_custom_prefix[prefix].append({
"layer_name": layer_name,
"total_time": total_time,
"compute": computing_time,
"load": loading_time,
"store": storeing_time
})
break
else:
mod_match = re.search(r'"Mod":\s*"([^"]+)"', layer_name)
if not mod_match:
continue
mod_path = mod_match.group(1)
mod_prefix = mod_path.split('.')[0]
grouped_by_custom_prefix[mod_prefix].append({
"layer_name": layer_name,
"mod_path": mod_path,
"total_time": total_time,
"compute": computing_time,
"load": loading_time,
"store": storeing_time
})
for prefix, ops in grouped_by_custom_prefix.items():
ops_sorted = sorted(ops, key=lambda x: x["total_time"], reverse=True)
# 保护文件名不与已有目录冲突
sanitized_prefix = prefix.replace("/", "_")
filename = f"{sanitized_prefix}_timing_report.csv"
csv_path = os.path.join(csv_output_dir, filename)
# 如果路径是个目录,加后缀防冲突
if os.path.isdir(csv_path):
csv_path += "_file.csv"
with open(csv_path, mode='w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(["layer_name", "total_time(us)", "compute(us)", "load(us)", "store(us)"])
for op in ops_sorted:
writer.writerow([op["layer_name"], f"{op['total_time']:.2f}", f"{op['compute']:.2f}", f"{op['load']:.2f}", f"{op['store']:.2f}"])
# ========== 分析层与类型耗时 ==========
def analyze_json_data(json_data, model=True):
layer_costs = []
type_costs = defaultdict(float)
type_compute_costs = defaultdict(float)
type_ddr_costs = defaultdict(float)
total_computing = 0
total_loading = 0
total_storing = 0
for layer in json_data.get("layer details", []):
layer_name = layer.get("layer name", "")
computing_cost = layer.get("computing cost (no DDR)", "0")
load_cost = layer.get("load cost", "0")
store_cost = layer.get("store cost", "0")
computing_time = parse_time(computing_cost)
loading_time = parse_time(load_cost)
storeing_time = parse_time(store_cost)
total_computing += computing_time
total_loading += loading_time
total_storing += storeing_time
total_time = computing_time + loading_time + storeing_time
ddr_time = loading_time + storeing_time
layer_costs.append((layer_name, total_time))
# if "model.head.det_head" in layer_name:
# print(layer_name)
op_match = re.search(r'\"OP\":\s*\"([^\"]+)\"', layer_name)
if op_match:
op_type = op_match.group(1)
restr = re.match(r'^([^./]+[./][^./]+)', op_type)
else:
# op_type = layer_name
last_part = layer_name.split('/')[-1]
# 提取前缀中的字母部分,比如 Where1 -> Where
match = re.match(r"([A-Za-z]+)", last_part)
op_type = match.group(1) if match else None
restr=None
if restr and model:
key = restr.group(1)
else:
key = op_type
if "HzCalibration" in layer_name:
key="HzCalibration"
type_costs[key] += total_time
type_compute_costs[key] += computing_time
type_ddr_costs[key] += ddr_time
return layer_costs, type_costs, total_computing, total_loading, total_storing, type_compute_costs, type_ddr_costs
# ========== 主函数 ==========
def main(path):
filename = path
args=sys.argv
with open(filename, 'r', encoding='utf-8') as file:
data = json.load(file)
log("="*30, "模型信息", "="*30)
log("计算量: ", round(data['summary']['model info']['original conv ops'] / 10**9, 2), 'Gops')
log("延迟: ", round(1000 / data['summary']['performance']['FPS'], 2), "ms")
log("HBDK版s本号: ", data['summary']['model info']['compiling HBDK version'])
log("BPU March: ", data['summary']['model info']['BPU march'])
log("平均带宽: ", round(data['summary']['DDR access data']['DDR bytes per second'] / 2**30, 2), 'GB/s')
json_data = data['summary']
layer_costs, type_costs, total_computing, total_loading, total_storing, type_compute_costs, type_ddr_costs = analyze_json_data(json_data)
top_layers = sorted(layer_costs, key=lambda x: x[1], reverse=True)[:20]
sorted_types = sorted(type_costs.items(), key=lambda x: x[1], reverse=True)
log("\n模型总耗时统计:")
log(f"计算耗时(no DDR): {total_computing:.2f} us")
log(f"load耗时: {total_loading:.2f} us")
log(f"store耗时: {total_storing:.2f} us")
log(f"总耗时: {total_computing + total_loading + total_storing:.2f} us")
log("="*70)
log("\n按类型统计的总耗时:")
log(f"{'op_type':<71} {'总耗时(us)':<15} {'计算耗时(us)':<15} {'ddr耗时(us)':<15}")
log("-" * 150)
sum_time = 0
sum_compute_costs = 0
sum_ddr_costs = 0
for op_type, time in sorted_types:
sum_time += type_costs[op_type]
sum_compute_costs += type_compute_costs[op_type]
sum_ddr_costs += type_ddr_costs[op_type]
log(f"{op_type:<70}: {type_costs[op_type]:>10.2f} {type_compute_costs[op_type]:>15.2f} {type_ddr_costs[op_type]:>15.2f}")
log('-' * 150)
log(f"sum_time: {sum_time:.2f} us sum_compute_costs: {sum_compute_costs:.2f} us sum_ddr_cost: {sum_ddr_costs:.2f} us")
log("\n耗时Top 20的layer: ")
for i, (layer_name, time) in enumerate(top_layers, 1):
log(f"{i}. 耗时: {time:.2f} us")
log(f" Layer名称: {layer_name}")
log()
# import pdb;pdb.set_trace()
# if args[1]== "qat":
# analyze_and_save_layer_by_mod_qat(json_data)
# elif args[1]=="ptq":
# analyze_and_save_layer_by_mod_ptq(json_data)
# selected_prefixes = ["lightmap_/img_backbone","lightmap_/img_neck","lightmap_/tf_local_encoder","lightmap_/frustum_to_voxel/","sparse4d_model.head", "sparse4d_model.img_neck"]
# analyze_selected_mod_prefixes(json_data,selected_prefixes)
# ========== 入口 ==========
if __name__ == '__main__':
path = 'perf.json'
main(path)*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
